Gaussian Splatting 测试+代码解读
[toc]
常见文件结构
1
2
3
4
5
6
7
8
|-dataset
|-images
|-sparse
|-0
|-cameras.bin # 相机内参
|-points3D.bin # colmap经BA之后mapper生成的点云
|-images.bin # 图像信息
自拍摄小场景测试结果
测试输入:
1
图像194帧(640, 480), colmap生成的初始点云点的数量:5.4k
测试结果(粗略的计时, 因为这其中包含了加载和保存文件的时间):
1
2
7k-iter 5min
30k-iter 30min
测试训练结果
1
./SIBR_viewers/install/bin/SIBR_gaussianViewer_app -m /home/lab/gs/output/bicycle/ -path /home/lab/gs/360_v2/bicycle
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
(gs) lab@lab-PC:~/workspace/cxx/gaussian-splatting$ python train.py -s /home/lab/gs/360_v2/bicycle -m /home/lab/gs/output/bicycle
Optimizing /home/lab/gs/output/bicycle
Output folder: /home/lab/gs/output/bicycle [06/12 19:00:54]
Tensorboard not available: not logging progress [06/12 19:00:54]
Reading camera 194/194 [06/12 19:00:54]
Converting point3d.bin to .ply, will happen only the first time you open the scene. [06/12 19:00:54]
Loading Training Cameras [06/12 19:00:54]
[ INFO ] Encountered quite large input images (>1.6K pixels width), rescaling to 1.6K.
If this is not desired, please explicitly specify '--resolution/-r' as 1 [06/12 19:00:54]
Loading Test Cameras [06/12 19:01:55]
Number of points at initialisation : 54275 [06/12 19:01:55]
Training progress: 23%|██████████████████████████████████████████████▏ | 7000/30000 [03:52<18:27, 20.76it/s, Loss=0.0939351]
[ITER 7000] Evaluating train: L1 0.03885948732495308 PSNR 23.782460403442386 [06/12 19:05:48]
[ITER 7000] Saving Gaussians [06/12 19:05:48]
Training progress: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30000/30000 [30:02<00:00, 16.65it/s, Loss=0.0589145]
[ITER 30000] Evaluating train: L1 0.026784038916230202 PSNR 27.015393829345705 [06/12 19:31:58]
[ITER 30000] Saving Gaussians [06/12 19:31:58]
Training complete. [06/12 19:32:19]
/scene/colmap_loader.cpp 中有函数write_points3D_binary用于将一组三维点云(point3D)写入.bin文件中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def write_points3D_binary(points3D, path_to_model_file):
"""
see: src/colmap/scene/reconstruction.cc
void Reconstruction::ReadPoints3DBinary(const std::string& path)
void Reconstruction::WritePoints3DBinary(const std::string& path)
"""
with open(path_to_model_file, "wb") as fid:
write_next_bytes(fid, len(points3D), "Q")
for _, pt in points3D.items():
write_next_bytes(fid, pt.id, "Q")
write_next_bytes(fid, pt.xyz.tolist(), "ddd")
write_next_bytes(fid, pt.rgb.tolist(), "BBB")
write_next_bytes(fid, pt.error, "d")
track_length = pt.image_ids.shape[0]
write_next_bytes(fid, track_length, "Q")
for image_id, point2D_id in zip(pt.image_ids, pt.point2D_idxs):
write_next_bytes(fid, [image_id, point2D_id], "ii"),
另一个函数用来读取bin文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
def read_points3D_binary(path_to_model_file):
"""
see: src/base/reconstruction.cc
void Reconstruction::ReadPoints3DBinary(const std::string& path)
void Reconstruction::WritePoints3DBinary(const std::string& path)
"""
with open(path_to_model_file, "rb") as fid:
num_points = read_next_bytes(fid, 8, "Q")[0]
xyzs = np.empty((num_points, 3))
rgbs = np.empty((num_points, 3))
errors = np.empty((num_points, 1))
for p_id in range(num_points):
binary_point_line_properties = read_next_bytes(
fid, num_bytes=43, format_char_sequence="QdddBBBd")
xyz = np.array(binary_point_line_properties[1:4])
rgb = np.array(binary_point_line_properties[4:7])
error = np.array(binary_point_line_properties[7])
track_length = read_next_bytes(
fid, num_bytes=8, format_char_sequence="Q")[0] # "image_ids",
track_elems = read_next_bytes(
fid, num_bytes=8*track_length,
format_char_sequence="ii"*track_length) # "point2D_idxs"
xyzs[p_id] = xyz
rgbs[p_id] = rgb
errors[p_id] = error
return xyzs, rgbs, errors
观察这两个函数可以发现,在读取.bin文件后,仅使用了其中的xyz,rgb,error这三个属性。所以如果使用已有的三维点云来替换colmap的生成结果, 该点云需要包含下列属性:
1
2
3
- (n,3)的点云坐标xyz,
- (n,3)的颜色rgbs,
- (n,1)的errors,其中errors的值全部为0. 创建一组points3D,填充其属性,使其可以使用write_points3D_binary写入为一个bin文件,同时还能够被read_points3D_binary读取。
colmap输出的文件可以保存为二进制文件(.bin)也可以保存为文本文件(.txt), 唯一区别只有是否方便人类阅读。
# 3D point list with one line of data per point: # POINT3D_ID, X, Y, Z, R, G, B, ERROR, TRACK[] as (IMAGE_ID, POINT2D_IDX) # Number of points: 3, mean track length: 3.3334 63390 1.67241 0.292931 0.609726 115 121 122 1.33927 16 6542 15 7345 6 6714 14 7227 63376 2.01848 0.108877 -0.0260841 102 209 250 1.73449 16 6519 15 7322 14 7212 8 3991 63371 1.71102 0.28566 0.53475 245 251 249 0.612829 118 4140 117 4473
其中的errors是重投影误差,是估计的3D点投影到图像之后的位置与实际观测的位置之间欧氏距离(是小数是因为3D点投影到2D图像后大概率得到的是一个浮点数坐标)。如果3D点是深度图像反投影得到的,同时深度图和彩色图像已经完成了对齐,那么理论上errors应该为0.
train 分析
初始化参数
1
2
3
lp = ModelParams(parser) # 模型参数(源数据)
op = OptimizationParams(parser) # 优化参数(包含学习率等)
pp = PipelineParams(parser)
其中ModelParams主要包含
PipelineParams中convert_SHs_python和compute_cov3D_python是在init时控制谐波颜色与三维协方差的预计算
1
2
3
4
5
6
class PipelineParams(ParamGroup):
def __init__(self, parser):
self.convert_SHs_python = False
self.compute_cov3D_python = False
self.debug = False
super().__init__(parser, "Pipeline Parameters")
如果提供了预计算的颜色(override_color),使用它们。否则,如果希望在Python中从SH中预计算颜色#,请执行此操作。如果不执行此操作,则SH->RGB转换将由光栅化器完成。
1
2
3
4
5
6
7
8
9
10
11
12
13
# If precomputed colors are provided, use them. Otherwise, if it is desired to precompute colors
# from SHs in Python, do it. If not, then SH -> RGB conversion will be done by rasterizer.
shs = None
colors_precomp = None
if override_color is None:
if pipe.convert_SHs_python:
shs_view = pc.get_features.transpose(1, 2).view(-1, 3, (pc.max_sh_degree+1)**2)
dir_pp = (pc.get_xyz - viewpoint_camera.camera_center.repeat(pc.get_features.shape[0], 1))
dir_pp_normalized = dir_pp/dir_pp.norm(dim=1, keepdim=True)
sh2rgb = eval_sh(pc.active_sh_degree, shs_view, dir_pp_normalized)
colors_precomp = torch.clamp_min(sh2rgb + 0.5, 0.0)
else:
shs = pc.get_features
#如果提供了预先计算的三维协方差,请使用它。如果没有,则光栅化器将根据#缩放/旋转来计算它。
1
2
if pipe.compute_cov3D_python:
cov3D_precomp = pc.get_covariance(scaling_modifier)
training flow
1
def training(dataset, opt, pipe, testing_iterations, saving_iterations, checkpoint_iterations, checkpoint, debug_from):
与输入的参数对应
1
training(lp.extract(args), op.extract(args), pp.extract(args), args.test_iterations, args.save_iterations, args.checkpoint_iterations, args.start_checkpoint, args.debug_from)
我们可以拿到对应关系
1
2
3
4
5
6
7
8
dataset - lp.extract(args)
opt - op.extract(args)
pipe - pp.extract(args)
testing_iterations - args.test_iterations
saving_iterations - args.save_iterations
checkpoint_iterations - args.checkpoint_iterations
checkpoint - args.start_checkpoint
debug_from - args.debug_from
首先来到dataset参数, 其用于各种初始化,lp来自
1
lp = ModelParams(parser) # 模型参数(源数据)
其中保存了模型的源数据, 其中存储了3dgs模型的图像路径、模型路径、解析度
1
2
3
4
5
6
7
8
9
10
11
class ModelParams(ParamGroup):
def __init__(self, parser, sentinel=False):
self.sh_degree = 3
self._source_path = ""
self._model_path = ""
self._images = "images"
self._resolution = -1
self._white_background = False
self.data_device = "cuda"
self.eval = False
super().__init__(parser, "Loading Parameters", sentinel)
比较重要的一点是dataset的sh_degree属性初始化了GaussianModel的max_sh_degree
1
gaussians = GaussianModel(dataset.sh_degree)
关于保存
默认是在迭代的7k和30k轮进行保存, 来看一下保存了什么, SIBR_Viewer又依赖什么来进行可视化。
1
parser.add_argument("--save_iterations", nargs="+", type=int, default=[7_000, 30_000])
参数经过传递后, 对应的是training函数中的saving_iterations, 由此我们可以很容易定位到:
1
2
3
if (iteration in saving_iterations):
print("\n[ITER {}] Saving Gaussians".format(iteration))
scene.save(iteration)
我们都知道, scene是包含了dataset和gaussian模型的一个对象,
1
2
gaussians = GaussianModel(dataset.sh_degree)
scene = Scene(dataset, gaussians)
1
2
3
def save(self, iteration):
point_cloud_path = os.path.join(self.model_path, "point_cloud/iteration_{}".format(iteration))
self.gaussians.save_ply(os.path.join(point_cloud_path, "point_cloud.ply"))
注意这个save_ply是GaussianModel类的函数, 因此整个保存的过程其实是独立于Scene的, 我们只需要关注GaussianModel即可,最重要的是, 对于其他衍生的工作, 我们只需要找到对应的GaussianModel使用save_ply, 保存xyz, _feature_xx等等属性即可使用SIBR进行可视化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def save_ply(self, path):
mkdir_p(os.path.dirname(path)) # 传递ply路径
xyz = self._xyz.detach().cpu().numpy()
normals = np.zeros_like(xyz)
f_dc = self._features_dc.detach().transpose(1, 2).flatten(start_dim=1).contiguous().cpu().numpy()
f_rest = self._features_rest.detach().transpose(1, 2).flatten(start_dim=1).contiguous().cpu().numpy()
opacities = self._opacity.detach().cpu().numpy()
scale = self._scaling.detach().cpu().numpy()
rotation = self._rotation.detach().cpu().numpy()
dtype_full = [(attribute, 'f4') for attribute in self.construct_list_of_attributes()]
elements = np.empty(xyz.shape[0], dtype=dtype_full)
attributes = np.concatenate((xyz, normals, f_dc, f_rest, opacities, scale, rotation), axis=1)
elements[:] = list(map(tuple, attributes))
el = PlyElement.describe(elements, 'vertex')
PlyData([el]).write(path)
可以看到, 保存的是每个gs的坐标, 法向, feature_dc, feautre_rest, 透射率opac, 尺寸scale, 旋转rot, 最终拼接成了一个(n, m)的点云形式。
对应output路径下的结构是
1
2
3
4
5
6
7
8
9
10
|-output_path
|-point_cloud
|-iteration_7000
|-point_cloud.ply
|-iteration_30000
|-point_cloud.ply
|-cameras.json
|-cfg_args
|-events.out.tfevents.xxxxx # log文件
|-input.ply
读取数据
以colmap格式的为例, 从images.bin读取每一帧图像对应的相机外参, 也就是相机的位姿。从cameras.bin读取相机的内参。
1
2
3
4
5
6
7
8
9
10
11
def readColmapSceneInfo(path, images, eval, llffhold=8):
try:
cameras_extrinsic_file = os.path.join(path, "sparse/0", "images.bin")
cameras_intrinsic_file = os.path.join(path, "sparse/0", "cameras.bin")
cam_extrinsics = read_extrinsics_binary(cameras_extrinsic_file)
cam_intrinsics = read_intrinsics_binary(cameras_intrinsic_file)
except:
cameras_extrinsic_file = os.path.join(path, "sparse/0", "images.txt")
cameras_intrinsic_file = os.path.join(path, "sparse/0", "cameras.txt")
cam_extrinsics = read_extrinsics_text(cameras_extrinsic_file)
cam_intrinsics = read_intrinsics_text(cameras_intrinsic_file)
cam_extrinsics为dict, keys为图像的序号, 从1开始计数。value部分是scene.colmap_loader.Image, 其包含多个属性
1
2
3
4
5
6
7
scene.colmap_loader.Image
-id: # 图像id
-qvec: # 相机外参旋转的四元数
-tvec: # 相机外参位移向量
-camera_id # 对应cam_intrinsics中的Camera对象的id
-xys: # (n_i, 2)
-point3D_ids: # (n_i, )
xys应该是3D点投影到2D平面上的2D坐标。 point3D_ids应该是与pointcloud文件中点云点的对应关系, 即对应3D点的下标。如果是-1,说明该3D点在该图像中不可见。
readColmapCameras
该函数输出cam_infos,
使用enumerate将从0开始的序号与图像顺序组织, 根据变量名称可以发现:images.bin存储的是相机的外参,cameras.bin存储的是内参。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
def readColmapSceneInfo(path, images, eval, llffhold=8):
try:
cameras_extrinsic_file = os.path.join(path, "sparse/0", "images.bin")
cameras_intrinsic_file = os.path.join(path, "sparse/0", "cameras.bin")
cam_extrinsics = read_extrinsics_binary(cameras_extrinsic_file)
cam_intrinsics = read_intrinsics_binary(cameras_intrinsic_file)
except:
cameras_extrinsic_file = os.path.join(path, "sparse/0", "images.txt")
cameras_intrinsic_file = os.path.join(path, "sparse/0", "cameras.txt")
cam_extrinsics = read_extrinsics_text(cameras_extrinsic_file)
cam_intrinsics = read_intrinsics_text(cameras_intrinsic_file)
reading_dir = "images" if images == None else images
cam_infos_unsorted = readColmapCameras(cam_extrinsics=cam_extrinsics, cam_intrinsics=cam_intrinsics, images_folder=os.path.join(path, reading_dir))
cam_infos = sorted(cam_infos_unsorted.copy(), key = lambda x : x.image_name)
if eval:
train_cam_infos = [c for idx, c in enumerate(cam_infos) if idx % llffhold != 0]
test_cam_infos = [c for idx, c in enumerate(cam_infos) if idx % llffhold == 0]
else:
train_cam_infos = cam_infos
test_cam_infos = []
nerf_normalization = getNerfppNorm(train_cam_infos)
ply_path = os.path.join(path, "sparse/0/points3D.ply")
bin_path = os.path.join(path, "sparse/0/points3D.bin")
txt_path = os.path.join(path, "sparse/0/points3D.txt")
if not os.path.exists(ply_path):
print("Converting point3d.bin to .ply, will happen only the first time you open the scene.")
try:
xyz, rgb, _ = read_points3D_binary(bin_path)
except:
xyz, rgb, _ = read_points3D_text(txt_path)
storePly(ply_path, xyz, rgb)
try:
pcd = fetchPly(ply_path) # 此处可以直接替换pcd, 只需要提供np.array的3个: positions(n,3) 'float32', colors(n, 3) 'float64' 0~1, normals(n,3) 'float32' 0,0,0, BasicPointCloud(points=positions, colors=colors, normals=normals)
except:
pcd = None
scene_info = SceneInfo(point_cloud=pcd, # 点云: xyzs, colors, normals
train_cameras=train_cam_infos, # cam_info
test_cameras=test_cam_infos, # []
nerf_normalization=nerf_normalization, # translate(centuralize), radius(max dist*1.1)
ply_path=ply_path) # path
return scene_info
相机外参 & images.bin
主要聚焦在相机外参部分, 其中较难理解的部分在于xys和point3D_ids
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
def read_extrinsics_binary(path_to_model_file):
"""
see: src/base/reconstruction.cc
void Reconstruction::ReadImagesBinary(const std::string& path)
void Reconstruction::WriteImagesBinary(const std::string& path)
"""
images = {}
with open(path_to_model_file, "rb") as fid:
num_reg_images = read_next_bytes(fid, 8, "Q")[0]
for _ in range(num_reg_images):
binary_image_properties = read_next_bytes(
fid, num_bytes=64, format_char_sequence="idddddddi")
image_id = binary_image_properties[0]
qvec = np.array(binary_image_properties[1:5])
tvec = np.array(binary_image_properties[5:8])
camera_id = binary_image_properties[8]
image_name = ""
current_char = read_next_bytes(fid, 1, "c")[0]
while current_char != b"\x00": # look for the ASCII 0 entry
image_name += current_char.decode("utf-8")
current_char = read_next_bytes(fid, 1, "c")[0]
num_points2D = read_next_bytes(fid, num_bytes=8,
format_char_sequence="Q")[0]
x_y_id_s = read_next_bytes(fid, num_bytes=24*num_points2D,
format_char_sequence="ddq"*num_points2D)
xys = np.column_stack([tuple(map(float, x_y_id_s[0::3])),
tuple(map(float, x_y_id_s[1::3]))])
point3D_ids = np.array(tuple(map(int, x_y_id_s[2::3])))
images[image_id] = Image(
id=image_id, qvec=qvec, tvec=tvec,
camera_id=camera_id, name=image_name,
xys=xys, point3D_ids=point3D_ids)
return images
二进制文件的读取函数是与写入函数write_extrinsics_binary是成对的, 写入的部分其实看起来更清晰一点。这部分的代码其实来自于colmap的二进制文件读写。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def write_extrinsics_binary(path_to_output_file, images):
"""
'extrinsics' in this loader corresponds to 'images'
write code from
https://github.com/colmap/colmap/blob/8e7093d22b324ce71c70d368d852f0ad91743808/scripts/python/read_write_model.py#L336C1-L354C60
"""
with open(path_to_output_file, "wb") as fid:
write_next_bytes(fid, len(images), "Q")
for _, img in images.items():
write_next_bytes(fid, img.id, "i")
write_next_bytes(fid, img.qvec.tolist(), "dddd")
write_next_bytes(fid, img.tvec.tolist(), "ddd")
write_next_bytes(fid, img.camera_id, "i")
for char in img.name:
write_next_bytes(fid, char.encode("utf-8"), "c")
write_next_bytes(fid, b"\x00", "c")
write_next_bytes(fid, len(img.point3D_ids), "Q")
for xy, p3d_id in zip(img.xys, img.point3D_ids):
write_next_bytes(fid, [*xy, p3d_id], "ddq")
write_next_bytes函数的第三个参数可以参阅struct.py, 简单来说, 其作为格式字符串指示第二个参数应该如何转换为二进制格式存储。例如:
| format | C type | python type | size(bytes) |
|---|---|---|---|
| Q | unsigned long long | int | 8 |
| i | signed int | int | 4 |
| c | char | string(len==1) | 1 |
| ddd | double*3 | 8*3 | |
| dddd | double*4 | 8*4 | |
| ddq | double*2, long long | 8*2+8 |
2025.1.9补充
在修改保存points3D代码时遇到了“BBB”的情况。
1
2
3
def write_points3D_binary(points3D, path_to_model_file):
...
write_next_bytes(fid, pt.rgb.tolist(), "BBB")
所谓BBB其实是表示Byte Byte Byte, 这里对应的含义是将RGB使用3个字节也就是3×8位表示, 即每个通道是0~255的。
看最后的几行可以发现, 格式字符串支持多个格式的组合。
有了这个表格, 理解写入函数就更加容易了。对于images中的每一项, 向输出的images.bin文件中写入图像的id, qvec, tvec, camera_id, 以及图像的name拆分成多个char, 完成后写入了一个b”\x00”, 这里的b表示byte, 表示后面是byte的编码。\x00是一个特殊的字节, \x为转义字符, 00表示该字节的值为0。b\x00对应空字符null character, 表示name的结束,因为name往往不是定长的。在读取的过程中, 用current_char != b”\x00”来判断name的读取是否结束。
核心的部分在于每一项的最后的代码,也就是下面展示的部分,首先写入当前帧图像中对应的三维点的数量len(img.point3D_ids)。这里写入的len(img.point3D_ids)对应读取代码中num_points2D, 可以发现这里存储的值是三维点云在当前相机视角画面上对应的2D点的数量。使用zip将xys和p3d_id这两个长度相同的list打包为一对一的元组, ([x, y], p3d_id)循环写入.bin文件中,可以看到一组是一个ddq, 长度为24字节。
1
2
3
write_next_bytes(fid, len(img.point3D_ids), "Q")
for xy, p3d_id in zip(img.xys, img.point3D_ids):
write_next_bytes(fid, [*xy, p3d_id], "ddq")
我们同样找到对应的读取部分代码,可以看到x_y_id_s是根据num_points2D的值来修改读取参数的, format_char_sequence是将"ddq"*num_points2D, 读取时候也是按24个字节来读,但是x_y_id_s是根据num_points2D的值将上面的for循环中存储的全部一次读取出来。
1
2
3
4
5
6
7
num_points2D = read_next_bytes(fid, num_bytes=8,
format_char_sequence="Q")[0]
x_y_id_s = read_next_bytes(fid, num_bytes=24*num_points2D,
format_char_sequence="ddq"*num_points2D)
xys = np.column_stack([tuple(map(float, x_y_id_s[0::3])),
tuple(map(float, x_y_id_s[1::3]))])
point3D_ids = np.array(tuple(map(int, x_y_id_s[2::3])))
可以看到, 针对读取到的tuple类型的数据x_y_id_s, 使用切片操作[x::3], 从下标x开始, 每隔3个元素取一个。得到的xys经过列堆叠之后变为(num_points2D, 2)的数组, point3D_ids变为(num_points2D, )的数组。
最终, 加载image.bin文件的函数read_extrinsics_binary返回值是结构如下的字典, key为image_id, value为对应的Image对象。
1
2
3
4
5
6
...
images[image_id] = Image(
id=image_id, qvec=qvec, tvec=tvec,
camera_id=camera_id, name=image_name,
xys=xys, point3D_ids=point3D_ids)
return images
对齐数据
当readColmapSceneInfo函数读取完images.bin与cameras.bin之后,使用了函数readColmapCameras来进行数据的对齐, 值得注意的是,在读取完之后使用sorted按照image_name进行了排序。
1
2
cam_infos_unsorted = readColmapCameras(cam_extrinsics=cam_extrinsics, cam_intrinsics=cam_intrinsics, images_folder=os.path.join(path, reading_dir))
cam_infos = sorted(cam_infos_unsorted.copy(), key = lambda x : x.image_name)
enumerate针对cam_extrinsics生成下标+key的组合, 因为python中key被认为是字典的组要元素, value被视为key的附属信息,所以enumerate默认只会遍历dict的key。因此,每次循环中的idx为序号,key为image_id, 可以看到,key去直接提取cam_extrinsics中的对应元素,而对于相机内参,则是用extr.camera_id去提取的,也就是说cam_extrinsics中的camera_id和cam_intrinsics的id是映射关系。两者的id并非是相同的意思,也并不能保证是按顺序一一对应的。
1
2
3
4
5
6
7
8
for idx, key in enumerate(cam_extrinsics):
sys.stdout.write('\r')
# the exact output you're looking for:
sys.stdout.write("Reading camera {}/{}".format(idx+1, len(cam_extrinsics)))
sys.stdout.flush()
extr = cam_extrinsics[key]
intr = cam_intrinsics[extr.camera_id]
| 循环的后半部分就是常规的计算外参的[R | T]矩阵, 根据记录的相机模型计算FOV, 主要任务是去读取了图片, 并保存图像的路径与图像名称。按照以下格式创建CameraInfo对象, 并存入cam_infos列表中, 作为函数的返回值。 |
1
2
cam_info = CameraInfo(uid=uid, R=R, T=T, FovY=FovY, FovX=FovX, image=image,
image_path=image_path, image_name=image_name, width=width, height=height)
一个示例:
1
2
3
4
5
6
7
8
9
10
11
CameraInfo(
uid=1802,
R=array([[ 0.39414302, 0.26409926, -0.88028567],
[-0.26546006, 0.94971142, 0.16606979],
[ 0.87987626, 0.16822544, 0.44442993]]),
T=array([ 2.96644424, -0.4039874 , 5.37197448]),
FovY=1.0899737893492698, FovX=1.3643063890069969,
image=<PIL.PngImagePlugin.PngImageFile image mode=RGB size=640x480 at 0x7FE456996820>,
image_path='/data4/cxx/dataset/gs/ismar/images/01801.png',
image_name='01801',
width=640, height=480)
其中, uid是来自对应的cam_intrinsics的相机的id
相机中心归一化
现在,回到readColmapSceneInfo函数,如果是eval模式, 使用llffhold参数对训练集和测试集进行划分。代码中可以看到, 是将idx与llffhold进行计算得到的。在此之前,cam_infos是cam_infos_unsorted通过sorted函数按图像名称进行了排序,也就是说,test用的相机视角是从整个视频序列里均匀采样得到的。
1
2
3
4
5
6
if eval:
train_cam_infos = [c for idx, c in enumerate(cam_infos) if idx % llffhold != 0]
test_cam_infos = [c for idx, c in enumerate(cam_infos) if idx % llffhold == 0]
else:
train_cam_infos = cam_infos
test_cam_infos = []
目前我们暂时还不关注eval, 继续到下面
1
nerf_normalization = getNerfppNorm(train_cam_infos)
直接上结论,该函数用于计算相机的归一化中心和平移。函数的目的是通过计算一组相机中心的平均值和对角线来确定归一化的平移和半径。其返回值为:
1
return {"translate": translate, "radius": radius}
其中
1
2
translate: np.array 相机到归一化中心的平移变换。直接将所有相机的坐标的均值点取反, 将现有的相机坐标直接与返回的translate相加,就能计算归一化后的相机中心坐标
radius: float 相机中心坐标的均值点到最远的相机中心点的距离 * 1.1
这一部分中比较重要的是:
1
2
3
4
for cam in cam_info:
W2C = getWorld2View2(cam.R, cam.T)
C2W = np.linalg.inv(W2C)
cam_centers.append(C2W[:3, 3:4])
| [R | T]是世界坐标系到相机坐标系的变换,并且计算出了相机坐标系到世界坐标系的变换。而用于去计算相机中心的坐标是C2W的位移部分。这是因为相机坐标系到世界坐标系的变换矩阵(C2W)中,位移变换就是相机中心在世界坐标系下的坐标。具体更详细的信息可以参考另一篇变换矩阵的笔记[link:spaceholder] |
加载点云
colmap的生成中, 法向normal全为0. 但是positions和colors都是有对应值的, colors是经过归一化的。
1
2
3
4
5
6
7
def fetchPly(path):
plydata = PlyData.read(path)
vertices = plydata['vertex']
positions = np.vstack([vertices['x'], vertices['y'], vertices['z']]).T
colors = np.vstack([vertices['red'], vertices['green'], vertices['blue']]).T / 255.0
normals = np.vstack([vertices['nx'], vertices['ny'], vertices['nz']]).T
return BasicPointCloud(points=positions, colors=colors, normals=normals)
这一步有对应的存储函数, 在自己生成的时候很容易生成:
1
def storePly(path, xyz, rgb):
camera_to_JSON
回到Scene的__init__函数, 当得到了scene_info后, 对其中的test和train相机,转换为JSON格式, 并且生成cameras.json文件
1
2
3
4
5
6
7
8
9
10
11
12
13
if not self.loaded_iter:
with open(scene_info.ply_path, 'rb') as src_file, open(os.path.join(self.model_path, "input.ply") , 'wb') as dest_file:
dest_file.write(src_file.read()) # 复制点云ply文件
json_cams = []
camlist = [] # 使用一个camlist按顺序存放test和train的相机
if scene_info.test_cameras:
camlist.extend(scene_info.test_cameras)
if scene_info.train_cameras:
camlist.extend(scene_info.train_cameras)
for id, cam in enumerate(camlist):
json_cams.append(camera_to_JSON(id, cam)) # 按顺序进行JSON转换并添加到json_cams
with open(os.path.join(self.model_path, "cameras.json"), 'w') as file:
json.dump(json_cams, file)
camera_json转换函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
def camera_to_JSON(id, camera : Camera):
Rt = np.zeros((4, 4))
Rt[:3, :3] = camera.R.transpose()
Rt[:3, 3] = camera.T
Rt[3, 3] = 1.0
W2C = np.linalg.inv(Rt)
pos = W2C[:3, 3]
rot = W2C[:3, :3]
serializable_array_2d = [x.tolist() for x in rot]
camera_entry = {
'id' : id,
'img_name' : camera.image_name,
'width' : camera.width,
'height' : camera.height,
'position': pos.tolist(),
'rotation': serializable_array_2d,
'fy' : fov2focal(camera.FovY, camera.height),
'fx' : fov2focal(camera.FovX, camera.width)
}
return camera_entry
之前的readColmapSceneInfo中的read_extrinsics_text函数中, 从二进制文件中读取相机的旋转qvec与位移tvec, 并且在readColmapCameras函数中, 计算了R和T
1
2
R = np.transpose(qvec2rotmat(extr.qvec)) # [w, x, y, z] -> 3×3 rotation matrix
T = np.array(extr.tvec)
而此时在camera_to_JSON中使用的camera.R和camera.T正是来自此处。
resolution scale
1
2
3
4
5
for resolution_scale in resolution_scales:
print("Loading Training Cameras")
self.train_cameras[resolution_scale] = cameraList_from_camInfos(scene_info.train_cameras, resolution_scale, args)
print("Loading Test Cameras")
self.test_cameras[resolution_scale] = cameraList_from_camInfos(scene_info.test_cameras, resolution_scale, args)
根据args.resolution和resolution_scale来对图像的分辨率进行调整。args.rosolution默认为-1, 即不缩放分辨率。
\[w_{scaled} = \frac{w_{origin}}{倍数*scale}\]根据最开始的if语句可以发现, 倍数一般是1,2,4,8
而且即便$args.resolution == -1$表示自动调整分辨率, 如果图像的宽度大于1600, 也会将其缩放到1600, 如果不希望缩放,可以将resolution参数设置为1来避免。注意区分args.resolution与resolution_scale
一般情况下, resolution_scale是不会更改的(1.0), 因为缩放因子的更改回使所有情况的图像分辨率缩放都发生变化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
def loadCam(args, id, cam_info, resolution_scale):
orig_w, orig_h = cam_info.image.size # 图像原始尺寸
# 原始尺寸/ (缩放倍数)
if args.resolution in [1, 2, 4, 8]:
resolution = round(orig_w/(resolution_scale * args.resolution)), round(orig_h/(resolution_scale * args.resolution))
else: # should be a type that converts to float
if args.resolution == -1:
if orig_w > 1600:
global WARNED
if not WARNED:
print("[ INFO ] Encountered quite large input images (>1.6K pixels width), rescaling to 1.6K.\n "
"If this is not desired, please explicitly specify '--resolution/-r' as 1")
WARNED = True
global_down = orig_w / 1600
else:
global_down = 1 # 图像尺寸小于1600, 不处理
else:
global_down = orig_w / args.resolution
scale = float(global_down) * float(resolution_scale)
resolution = (int(orig_w / scale), int(orig_h / scale))
并且检查有没有alpha通道(第4个通道, 作为mask)
1
2
3
4
5
6
7
8
9
10
11
12
resized_image_rgb = PILtoTorch(cam_info.image, resolution)
gt_image = resized_image_rgb[:3, ...]
loaded_mask = None
if resized_image_rgb.shape[1] == 4:
loaded_mask = resized_image_rgb[3:4, ...]
return Camera(colmap_id=cam_info.uid, R=cam_info.R, T=cam_info.T,
FoVx=cam_info.FovX, FoVy=cam_info.FovY,
image=gt_image, gt_alpha_mask=loaded_mask,
image_name=cam_info.image_name, uid=id, data_device=args.data_device)
经此, CameraInfo的list被转换为按不同分辨率缩放倍数存储的Camera的list
1
2
3
4
5
6
{
"1": [Camera(clomap_id, ...), Camera(), ...],
"2": [Camera(), Camera(), ...],
"4": [Camera(), Camera(), ...]
...
}
而Camera中存储的数据
1
2
3
4
return Camera(colmap_id=cam_info.uid, R=cam_info.R, T=cam_info.T,
FoVx=cam_info.FovX, FoVy=cam_info.FovY,
image=gt_image, gt_alpha_mask=loaded_mask,
image_name=cam_info.image_name, uid=id, data_device=args.data_device)
| Camera | cam_info | 备注 |
|---|---|---|
| colmap_id | uid | 对应的cam_intrinsics的相机的id |
| image | - | resize后的RGB图像 |
| gt_alpha_mask | - | 如果原本图像是有alpha通道的, 其alpha通道提取作为mask |
| uid | - | 遍历cam_infos时enumerate生成的index, 从0开始 |
| data_device | - | 一般是’cuda’ |
create_from_pcd
终于来到了生成3dgs的时刻, 输入点云和cameras_extent, cameras_extent又摇身一变成为了spatial_lr_scale. 而pcd则还是那个刚读取的状态, 包含points, colors, normals三个属性(虽然normals可能没有)
1
self.gaussians.create_from_pcd(scene_info.point_cloud, self.cameras_extent)
cameras_extent表示所有的相机中心点中距离均值点最远的点的距离的1.1倍, 参考相机中心归一化:
1
self.cameras_extent = scene_info.nerf_normalization["radius"]
RGB转换为球谐波SH, 转换函数似乎很简单, 而且转换前后都是(n, 3), 这很难不让人好奇:
- 球谐函数到底与RGB有什么不同?
- 参数C0是如何确定的?
1
fused_color = RGB2SH(torch.tensor(np.asarray(pcd.colors)).float().cuda())
1
2
3
4
5
6
7
C0 = 0.28209479177387814
def RGB2SH(rgb):
return (rgb - 0.5) / C0
def SH2RGB(sh):
return sh * C0 + 0.5
暂时先不考虑
fused_color: $(n, 3)$
features: $(n, 3, (msd+1)^2)$
1
2
3
features = torch.zeros((fused_color.shape[0], 3, (self.max_sh_degree + 1) ** 2)).float().cuda() # (n, 3, (sh+1)**2)
features[:, :3, 0 ] = fused_color
features[:, 3:, 1:] = 0.0
第2维度用fused_color赋值(也就是SH系数), 其他的通道赋值0, 但实际上第1维为3, 所以features[:, 3:, 1:] = 0.0其实没有发挥作用。
计算点云中每个点到其他店的最小距离dist2:torch.Size([n]), 使用torch.clamp_min将所有的元素限制在最小值10E-7以上. 然后对这些距离取平方根后计算对数
\[s_i = log(\sqrt{dist2})\] \[scales = (s_i, s_i, s_i)\]创建四元数表示的旋转(w, x, y, z), w置为1, 其他位为0.
1
2
3
4
dist2 = torch.clamp_min(distCUDA2(torch.from_numpy(np.asarray(pcd.points)).float().cuda()), 0.0000001)
scales = torch.log(torch.sqrt(dist2))[...,None].repeat(1, 3)
rots = torch.zeros((fused_point_cloud.shape[0], 4), device="cuda")
rots[:, 0] = 1
后续也是创建许多待用的对象, 在此我们先跳过。
点云被存储为_xyz, 此后可以被get_xyz函数获取, 之后会经常使用。
1
2
3
4
5
6
7
8
9
opacities = inverse_sigmoid(0.1 * torch.ones((fused_point_cloud.shape[0], 1), dtype=torch.float, device="cuda")) # (n, 1)的全0.1, 进行inverse_sigmoid
self._xyz = nn.Parameter(fused_point_cloud.requires_grad_(True))
self._features_dc = nn.Parameter(features[:,:,0:1].transpose(1, 2).contiguous().requires_grad_(True))
self._features_rest = nn.Parameter(features[:,:,1:].transpose(1, 2).contiguous().requires_grad_(True))
self._scaling = nn.Parameter(scales.requires_grad_(True))
self._rotation = nn.Parameter(rots.requires_grad_(True))
self._opacity = nn.Parameter(opacities.requires_grad_(True))
self.max_radii2D = torch.zeros((self.get_xyz.shape[0]), device="cuda")
至此, Scene初始化中的create_from_pcd结束, 初始化也已经完成。回到training函数, 等gs模型的training_setup完成, 迭代即将开始。
training_
可以看到, create_from_pcd中创建的大多数变量都在这里被加入到了$l$中,作为优化器的优化对象。但是学习率一开始被设置为0, 并且通过get_expon_lr_func创建了一个学习率衰减函数。
可以看到: 三维空间坐标、features_dc和rest, 缩放scaling, 旋转, 透射率(透明度)。 这些都是被优化器优化的对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def training_setup(self, training_args):
self.percent_dense = training_args.percent_dense # 百分比密度, 初始为0.01
self.xyz_gradient_accum = torch.zeros((self.get_xyz.shape[0], 1), device="cuda") # 各个点累计的梯度
self.denom = torch.zeros((self.get_xyz.shape[0], 1), device="cuda") # 各个点的分母
l = [
{'params': [self._xyz], 'lr': training_args.position_lr_init * self.spatial_lr_scale, "name": "xyz"},
{'params': [self._features_dc], 'lr': training_args.feature_lr, "name": "f_dc"},
{'params': [self._features_rest], 'lr': training_args.feature_lr / 20.0, "name": "f_rest"},
{'params': [self._opacity], 'lr': training_args.opacity_lr, "name": "opacity"},
{'params': [self._scaling], 'lr': training_args.scaling_lr, "name": "scaling"},
{'params': [self._rotation], 'lr': training_args.rotation_lr, "name": "rotation"}
]
self.optimizer = torch.optim.Adam(l, lr=0.0, eps=1e-15) # 学习率设置为0, 此时第一个参数l中的内容不会改变, 但是学习率在之后会更新
self.xyz_scheduler_args = get_expon_lr_func(lr_init=training_args.position_lr_init*self.spatial_lr_scale,
lr_final=training_args.position_lr_final*self.spatial_lr_scale,
lr_delay_mult=training_args.position_lr_delay_mult,
max_steps=training_args.position_lr_max_steps)
学习率衰减函数
get_expon_lr_func, expon->exponential(指数), 从注释中也能发现, “从lr_init到lr_final的对数线性插值”等同于“指数衰减”。
1
2
lr_init: 学习率的初始值
lr_final: 学习率下降的最终值
下面的两个参数要注意其参数名中的delay, delay了什么?延迟”学习率衰减”, 所谓的衰减是我们根据优化函数中学习率的下降与init和final得出来的。
1
2
3
lr_delay_steps: 学习率延迟衰减步数, 从多少步之后才会开始衰减学习率. 如果是0, 从一开始就开始衰减学习率, 如果是m, 则m步后才会开始衰减学习率。
lr_delay_mult: 学习率延迟衰减乘数(multipiler), 在延迟衰减学习率的阶段, 该乘数会与衰减率计算。
max_steps: 优化过程中的最大步数, 当到达max_steps, 学习率也会衰减到lr_final.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
def get_expon_lr_func(
lr_init, lr_final, lr_delay_steps=0, lr_delay_mult=1.0, max_steps=1000000
):
"""
Copied from Plenoxels
Continuous learning rate decay function. Adapted from JaxNeRF
The returned rate is lr_init when step=0 and lr_final when step=max_steps, and
is log-linearly interpolated elsewhere (equivalent to exponential decay).
If lr_delay_steps>0 then the learning rate will be scaled by some smooth
function of lr_delay_mult, such that the initial learning rate is
lr_init*lr_delay_mult at the beginning of optimization but will be eased back
to the normal learning rate when steps>lr_delay_steps.
:param conf: config subtree 'lr' or similar
:param max_steps: int, the number of steps during optimization.
:return HoF which takes step as input
"""
def helper(step):
if step < 0 or (lr_init == 0.0 and lr_final == 0.0):
# Disable this parameter
return 0.0
if lr_delay_steps > 0: # 在什么时候开始衰减学习率
# A kind of reverse cosine decay.
delay_rate = lr_delay_mult + (1 - lr_delay_mult) * np.sin(
0.5 * np.pi * np.clip(step / lr_delay_steps, 0, 1)
)
else:
delay_rate = 1.0
t = np.clip(step / max_steps, 0, 1)
log_lerp = np.exp(np.log(lr_init) * (1 - t) + np.log(lr_final) * t)
return delay_rate * log_lerp
return helper
乍一看, lr_delay_steps在整个函数中没有被赋值, 没有被修改, 那么只要其值大于0, 学习率岂不是会一直被delay? 实际上, $lr_delay_steps$是通过下面的公式$\min\left(\frac{step}{lr_delay_steps}, 1\right)$来控制何时停止”延迟学习率衰减”的。
看$lr_delay_steps>0$时的衰减率计算, 如果 \(delay\_rate = \begin{cases} lr\_delay\_mult + (1 - lr\_delay\_mult) \cdot \sin\left(\frac{\pi}{2} \cdot \min\left(\frac{step}{lr\_delay\_steps}, 1\right)\right) & \text{if } lr\_delay\_steps > 0 \\ 1 & \text{otherwise} \end{cases}\)
随着step逐渐增大, 超过$lr_delay_steps$时, $\sin$部分将始终为1, 当其为1的时候, $delay_rate = 1$, 和$lr_delay_steps <= 0$ 结果相同, 学习率开始衰减。
而延迟衰减阶段sin部分的计算结果是小于1的, \(delay\_rate = (1-\alpha)lr\_delay\_mult + \alpha\)
将$\alpha$视为固定值($<=1$), 衰减率$delay_rate$与$lr_delay_mult$线性相关, 并且$lr_delay_mult$为1时, 衰减率也等于1.
\[t = \min\left(\frac{step}{max\_steps}, 1\right)\]t用来表示迭代进度
\[log\_lerp = e^{(1 - t) \cdot \ln(lr\_init) + t \cdot \ln(lr\_final)}\]$log_lerp$: 对数线性插值, 冷知识lerp是线性插值(linear interpolation)的缩写
\[return = delay\_rate \cdot log\_lerp\]至此, 对数线性插值的学习率衰减函数helper完成, 作为get_expon_lr_func得到的”指数学习率函数”返回, 该函数保存为GaussianModel的xyz_scheduler_args.
补充:对数线性插值: 举一个最简单的对数线性插值例子, 在对数空间中, 在[0, 100]区间上, 步长为1, 对值y1, y2之间进行插值, 如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import numpy as np
import matplotlib.pyplot as plt
def log_linear_interpolation(y1, y2, t):
return np.exp((1 - t) * np.log(y1) + t * np.log(y2))
y1 = 1
y2 = 100
t = np.linspace(0, 1, 100)
y = log_linear_interpolation(y1, y2, t)
plt.plot(t, y)
plt.xlabel('t')
plt.ylabel('y')
plt.title('Log-linear interpolation')
plt.grid(True)
plt.show()
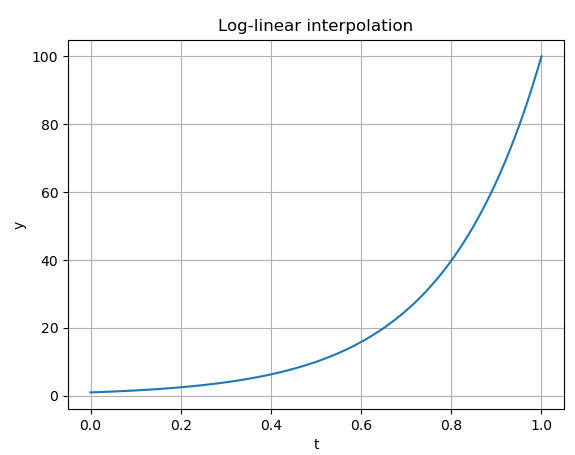
回到代码,生成的helper学习率衰减函数图像如下:
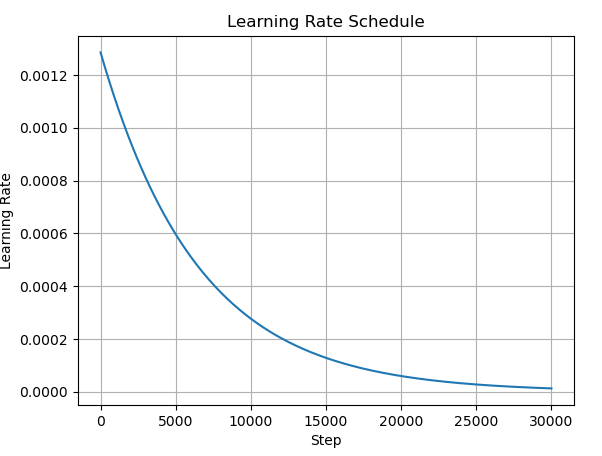
在默认的训练设置下, 这几个参数的数值如下:
1
2
3
4
5
lr_init: 0.0012860771789550782
lr_final: 1.286077178955078e-05
lr_delay_steps: 0
lr_delay_mult: 0.01
max_steps: 30000
我们绘制函数图像看一下:
绘制代码
~~~python import numpy as np import matplotlib.pyplot as plt lr_init = 0.0012860771789550782 lr_final = 1.286077178955078e-05 lr_delay_mult = 0.01 max_steps = 30000 lr_delay_steps = 0 def helper(step): if step < 0 or (lr_init == 0.0 and lr_final == 0.0): return 0.0 if lr_delay_steps > 0: delay_rate = lr_delay_mult + (1 - lr_delay_mult) * np.sin( 0.5 * np.pi * np.clip(step / lr_delay_steps, 0, 1) ) else: delay_rate = 1.0 t = np.clip(step / max_steps, 0, 1) log_lerp = np.exp(np.log(lr_init) * (1 - t) + np.log(lr_final) * t) return delay_rate * log_lerp steps = np.arange(0, max_steps) lr_values = [helper(step) for step in steps] plt.plot(steps, lr_values) plt.xlabel('Step') plt.ylabel('Learning Rate') plt.title('Learning Rate Schedule') plt.grid(True) plt.show()补充图像
迭代!
终于来到了迭代的环节, gaussians.update_learning_rate(iteration),进来后发现竟然比想象的要简单。
1
2
3
4
5
6
7
def update_learning_rate(self, iteration):
''' Learning rate scheduling per step '''
for param_group in self.optimizer.param_groups:
if param_group["name"] == "xyz":
lr = self.xyz_scheduler_args(iteration)
param_group['lr'] = lr
return lr
首先的self.optimizer.param_groups, optimizer就是学习率被设置为0的那个Adam优化器, 那么它的param_groups(list)也当然是我们之前在training_setup设置的那6个优化对象:
1
2
3
4
5
6
7
8
l = [
{'params': [self._xyz], 'lr': training_args.position_lr_init * self.spatial_lr_scale, "name": "xyz"},
{'params': [self._features_dc], 'lr': training_args.feature_lr, "name": "f_dc"},
{'params': [self._features_rest], 'lr': training_args.feature_lr / 20.0, "name": "f_rest"},
{'params': [self._opacity], 'lr': training_args.opacity_lr, "name": "opacity"},
{'params': [self._scaling], 'lr': training_args.scaling_lr, "name": "scaling"},
{'params': [self._rotation], 'lr': training_args.rotation_lr, "name": "rotation"}
]
观察代码可以发现, 在更新学习率时, 仅会使用之前创建的学习率衰减函数来更新xyz的学习率。
而每当迭代1000次, 使用oneupSHdegree函数来将active_sh_degree上调一级, 默认的训练设置下, max_sh_degree为3, 初始active_sh_degree为0.
1
2
3
# Every 1000 its we increase the levels of SH up to a maximum degree
if iteration % 1000 == 0:
gaussians.oneupSHdegree()
1
2
3
def oneupSHdegree(self):
if self.active_sh_degree < self.max_sh_degree:
self.active_sh_degree += 1
渲染
后面的结构就比较清晰了, 选择所有参与训练的相机视角, 随机删除其中的一部分(至少会保留一个), 使用gaussians,pipe和bg开始在剩下的视角viewpoint_cam进行渲染。
1
2
3
4
5
6
7
8
9
10
11
12
13
# Pick a random Camera 选取随机的训练cameras
if not viewpoint_stack:
viewpoint_stack = scene.getTrainCameras().copy()
viewpoint_cam = viewpoint_stack.pop(randint(0, len(viewpoint_stack)-1))
# Render
if (iteration - 1) == debug_from:
pipe.debug = True
bg = torch.rand((3), device="cuda") if opt.random_background else background
render_pkg = render(viewpoint_cam, gaussians, pipe, bg)
image, viewspace_point_tensor, visibility_filter, radii = render_pkg["render"], render_pkg["viewspace_points"], render_pkg["visibility_filter"], render_pkg["radii"]
渲染的输入是: 相机视角, 当前的gs, pipe, 背景bg
创建了一个和3D点云同样大小的tensor, 注释中提到要使用它来获得2D均值的梯度
1
2
3
4
5
6
# Create zero tensor. We will use it to make pytorch return gradients of the 2D (screen-space) means
screenspace_points = torch.zeros_like(pc.get_xyz, dtype=pc.get_xyz.dtype, requires_grad=True, device="cuda") + 0
try:
screenspace_points.retain_grad()
except:
pass
关于”3D协方差”
paper中提到: 以前的使用2D点的方法, 假设每一个点都是一个带有法线的平面圆, 但是当给了一组非常系数的SfM点时,很难估计法向, 从稀疏点钟去优化噪声很多的法向是很困难的。因此作者的3D高斯并不使用法向信息, 通过全三维协方差矩阵(full 3D covariance matrix, $\Sigma$)来定义Gaussian
\[G(x)=e^{-\frac{1}{2}(x)^T\Sigma^{-1}(x)}\]在blending过程中, 这个要乘以透明度$\alpha$
回到代码
如果没有预先计算的3D协方差, 需要使用scale和rotation来计算:
1
2
3
4
5
6
7
8
9
10
# If precomputed 3d covariance is provided, use it. If not, then it will be computed from
# scaling / rotation by the rasterizer.
scales = None
rotations = None
cov3D_precomp = None
if pipe.compute_cov3D_python:
cov3D_precomp = pc.get_covariance(scaling_modifier)
else:
scales = pc.get_scaling
rotations = pc.get_rotation
他们来自:
1
2
3
scales = torch.log(torch.sqrt(dist2))[...,None].repeat(1, 3)
rots = torch.zeros((fused_point_cloud.shape[0], 4), device="cuda")
rots[:, 0] = 1
同样的, 颜色这一部分, 默认训练设置中, override_color是None, pipe.convert_SHs_python是False, 因此会通过pc.get_features来获得SH相关的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# If precomputed colors are provided, use them. Otherwise, if it is desired to precompute colors
# from SHs in Python, do it. If not, then SH -> RGB conversion will be done by rasterizer.
shs = None
colors_precomp = None
if override_color is None:
if pipe.convert_SHs_python:
shs_view = pc.get_features.transpose(1, 2).view(-1, 3, (pc.max_sh_degree+1)**2)
dir_pp = (pc.get_xyz - viewpoint_camera.camera_center.repeat(pc.get_features.shape[0], 1))
dir_pp_normalized = dir_pp/dir_pp.norm(dim=1, keepdim=True)
sh2rgb = eval_sh(pc.active_sh_degree, shs_view, dir_pp_normalized)
colors_precomp = torch.clamp_min(sh2rgb + 0.5, 0.0)
else:
shs = pc.get_features
else:
colors_precomp = override_color
1
2
3
4
def get_features(self):
features_dc = self._features_dc
features_rest = self._features_rest
return torch.cat((features_dc, features_rest), dim=1)
最后得到的shs大小是torch.Size([n, 16, 3])
到这里, 准备工作就全部完成了, 扔到diff_gaussian_rasterization里面完成光栅化, 返回渲染结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
raster_settings = GaussianRasterizationSettings(
image_height=int(viewpoint_camera.image_height),
image_width=int(viewpoint_camera.image_width),
tanfovx=tanfovx,
tanfovy=tanfovy,
bg=self.bg_color if not invert_bg_color else 1 - self.bg_color,
scale_modifier=scaling_modifier,
viewmatrix=viewpoint_camera.world_view_transform,
projmatrix=viewpoint_camera.full_proj_transform,
sh_degree=self.gaussians.active_sh_degree,
campos=viewpoint_camera.camera_center,
prefiltered=False,
debug=False,
)
可以看到, 光栅化设置中, 使用了viewpoint_camera的image_height, image_width, world_view_transform, full_proj_transform和camera_center. 这些都是相机位姿相关的数据。
tile-based
1
2
3
#define NUM_CHANNELS 3 // Default 3, RGB
#define BLOCK_X 16
#define BLOCK_Y 16
创建了一个dim3格式的三维向量, $(\frac{W + B_x - 1}{B_x}, \frac{H + B_y - 1}{B_y}, 1)$
1
dim3 tile_grid((width + BLOCK_X - 1) / BLOCK_X, (height + BLOCK_Y - 1) / BLOCK_Y, 1);
而一个block的大小为$(B_x, B_y, 1)$
1
dim3 block(BLOCK_X, BLOCK_Y, 1);
一路来到了preprocessCUDA
而«<(P + 255) / 256, 256»> 是 CUDA 的执行配置语法,用于指定线程块的数量和每个线程块的线程数量。(P + 255) / 256 向上取整计算线程块数量,256 是每个线程块的线程数量。
同样P, H, W这三个参数也是在进入CUDA代码时就引入的, 分别是点云点的数量, 图像高度, 图像宽度
1
2
3
const int P = means3D.size(0);
const int H = image_height;
const int W = image_width;
means3D(n, 3)也就是归一化后的点云, 在CUDA的forward中变为了orig_points, 首先确定是否在frustum内, 如果不在直接退出。如果在视椎体内,按照idx作为索引去取第idx个点的x,y,z, 然后使用来自viewpoint_cam的投影矩阵, 将3D点投影到成像平面上.
1
2
3
4
5
// Transform point by projecting
float3 p_orig = { orig_points[3 * idx], orig_points[3 * idx + 1], orig_points[3 * idx + 2] };
float4 p_hom = transformPoint4x4(p_orig, projmatrix);
float p_w = 1.0f / (p_hom.w + 0.0000001f);
float3 p_proj = { p_hom.x * p_w, p_hom.y * p_w, p_hom.z * p_w };
注意得到的p_proj依然是一个三维向量
概念: 高斯的各向异性
各向异性(Anisotropy)与各向同性(Isotropic)是两个相对概念。提到各向异性同性可能会听过BRDF, 实际是涉及了方向性质的反射问题。
各向异性其实通俗说就是: 在各个方向上观察是不同的,各向同性就是各个方向观察是相同的。如果我们在三维空间中创建一个标准的圆球体, 那么这个球在几何上就是各向同性的,但仅是几何上, 如果涉及到纹理, 光线等方面, 可能并不是各向同性的。
3dgs论文中提到的高斯球的各项异性其实是针对几何来说的,是指表达高斯球的各个方向的协方差不同,使得高斯球是一个椭球,在不同的方向上会得到不同的观察结果,能够进一步表示不同的结果。 Q:guassing splatting的每一个椭球也有颜色,透射率等属性,为什么说各向异性仅是指几何? A:因为每个椭球的透射率和颜色,在vanilla 3dgs中是方向无关的, 不管从哪个方向观察,当前计算的椭球的透射率和颜色都是不会改变的。但是椭球则不同, 它会因为自身在各个方向的方差有不同的数据分布,从而使不同视角的观察结果发生变化,因此是各向异性的。
如果一个gs球是各向同性的,那么它在各个方向上的观察结果都是相同的,是一个空间中的标准球体。
2D, 3D协方差矩阵与公式6, 协方差矩阵为什么可以分解为R和S
参考:
https://stackoverflow.com/questions/65527024/create-covariance-matrix-using-ratio-and-rotation-degree
https://github.com/graphdeco-inria/gaussian-splatting/issues/392
首先, 协方差矩阵的性质:半正定,方阵, 实对称(实数+对称), 其中半正定意味着对于任何的非零向量$v$(假设$\Sigma$为$n$阶方阵, $v$为n维向量), 满足:
\[v \Sigma v^T \geq 0\]这个公式同时也意味着协方差矩阵的所有特征值都是非负的.
举例:
\[[b_1, b_2, b_3] \begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \\ \end{bmatrix} [b_1, b_2, b_3]^T \geq 0\]而协方差矩阵是对称的, 其转置等于自身, 因此$a_{ij}=a_{ji}$, 可以变为下面的形式
\[b_1^2*a_{11} + b_2^2*a_{22} + b_3^2*a_{33} + 2*b_1*b_2*a_{12} + 2*b_1*b_3*a_{13} + 2*b_2*b_3*a_{23} \geq 0\]因为$v$是非零向量, 因此所有的$a_{ij}$都是非负的。
设概率空间为$(\Omega, \Sigma, P)$, 有两个随机变量序列, $X={ x_i }^{m}{i=1}$和$Y={ y_i }^{m}{i=1}$, 其中的$x_i$和$y_i$都是随机变量。 例如:
$X={x_1, x_2}$, $Y={y_1, y_2}$
其中$x_i$和$y_i$都是表示为数组的随机变量, 包含一系列的观测值:
$x_1 = [2, 4, 6], x_2 = [1, 3, 5], y_1 = [5, 10 ,15], y_2 = [3, 6, 9]$
那么对应的期望为 $E(x_i)=\int_{\Omega} x_i dP$,
协方差描述两个随机变量之间的差异分布, 协方差矩阵是两列/组随机变量之间的协方差, 是协方差的推广。
这两组随机变量之间的协方差矩阵定义为:
\[cov(X, Y) := [cov(x_i, y_j)]_{m \times n} = [ E[(x_i - u_i)(y_j - v_j)] ]_{m \times n}\] \[cov(X, Y) := [ E[(X - E(X))(Y - E(Y))^T] ]\]协方差矩阵能够导出一个变换矩阵, 使数据完全去相关(decorrelation), 换句话说, 可以找出一组最佳的基, 以紧凑的方式表达数据。也就是主成分分析, KL-变换。参考: https://en.wikipedia.org/wiki/Covariance_matrix
参考: https://medium.com/@AriaLeeNotAriel/numbynum-3d-gaussian-splatting-for-real-time-radiance-field-rendering-kerbl-et-al-60c0b25e5544
渲染需要将3D Gaussian投影到2D, $J$是投影变换的仿射近似雅克比矩阵。$W$是投影变换。
\[\Sigma = JW\Sigma W^TJ^T\]如同论文中说的那样, 最直接的方法就是创建一个对称矩阵, 创建6个变量, 然后梯度下降去优化这6个值。a_{*}代表其值通过对称获得。
\[\Sigma = \begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{*} & a_{22} & a_{23} \\ a_{*} & a_{*} & a_{33} \\ \end{bmatrix}\]但是协方差矩阵必须是半正定的才有物理意义, 优化过程中很容易就会破坏协方差矩阵的半正定。
因此,作者提出了一种具有同样表达能力的优化表示来代替协方差矩阵, 即论文中的公式6, 介绍如何使用scale和rotation来计算协方差矩阵. 这一种各向异性的协方差表示适用于优化。公式6:
\[\Sigma=R S S^T R^T\]为什么这么做?因为利用下面的公式得到的矩阵总是满足半正定的, 这种操作/技巧被称为reparametrization(重参数化)。
\[\Sigma = A^T A\]因为对于任何的非零向量$v$, $Av$是一个维度为n的向量。
\[v^T\Sigma v = v^{T} (A^{T} A) v = (Av)^{T}Av = \|Av\|^{2} \geq 0\]Q: 为什么$A$被进一步分解为Scaling和Rotation?
因为论文的目标就是优化每个高斯椭球的参数来得到更好的可视化效果(PSNR等指标), 而每个高斯椭球都是由均值(中心点坐标), 协方差矩阵($\Sigma$)和不透明度参数$\alpha$来定义的, 协方差矩阵控制着椭球的形状和方向. 具体来说, 是Scaling和Rotation在分别控制着椭球的形状和方向。
将其使用$RS$组合成矩阵$A$只是为了维持协方差矩阵的半正定这一物理性质, 换句话说, 使用$R$和$S$来组合成$A$其实是人为设计的策略, 我完全可以创建一个矩阵A, 把四元数$q$和缩放向量$s$的一共7个值塞进去来创建一个A; 更甚至, 我可以将法向或者颜色或者其他的什么乱七八糟的塞到$A$中, 让其参与到梯度下降中去。
下面的CUDA代码使用scale和rotation来计算协方差矩阵
mod是scale_modifier, 来自
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
// Forward method for converting scale and rotation properties of each
// Gaussian to a 3D covariance matrix in world space. Also takes care
// of quaternion normalization.
__device__ void computeCov3D(const glm::vec3 scale, float mod, const glm::vec4 rot, float* cov3D)
{
// Create scaling matrix
glm::mat3 S = glm::mat3(1.0f); // 创建3×3零矩阵, scale赋值对角线元素
S[0][0] = mod * scale.x;
S[1][1] = mod * scale.y;
S[2][2] = mod * scale.z;
// Normalize quaternion to get valid rotation
glm::vec4 q = rot;// / glm::length(rot);
float r = q.x;
float x = q.y;
float y = q.z;
float z = q.w;
// Compute rotation matrix from quaternion // 四元数转旋转矩阵
glm::mat3 R = glm::mat3(
1.f - 2.f * (y * y + z * z), 2.f * (x * y - r * z), 2.f * (x * z + r * y),
2.f * (x * y + r * z), 1.f - 2.f * (x * x + z * z), 2.f * (y * z - r * x),
2.f * (x * z - r * y), 2.f * (y * z + r * x), 1.f - 2.f * (x * x + y * y)
);
glm::mat3 M = S * R; // 得到 scaling 和 rotation 矩阵的乘积
// Compute 3D world covariance matrix Sigma
glm::mat3 Sigma = glm::transpose(M) * M; // M^T M 计算协方差矩阵\Sigma
// Covariance is symmetric, only store upper right
cov3D[0] = Sigma[0][0];
cov3D[1] = Sigma[0][1];
cov3D[2] = Sigma[0][2];
cov3D[3] = Sigma[1][1];
cov3D[4] = Sigma[1][2];
cov3D[5] = Sigma[2][2];
}
仔细观察上面的代码, 可能会有疑问: 论文中的公式6写的是:
\[\Sigma=R S S^T R^T\]且附录中在介绍求导时提到:
\[M=RS\]并且($S$只有对角线是各个方向的缩放, 其他值为0, 是对称矩阵, 所以$S=S^T$)
\[\Sigma = MM^T = RSS^TR^T = RSSR^T\]和公式6一致。
而这个代码的实现中:
\[M = SR\] \[\Sigma = M^T M = R^TS^TSR = R^TSSR\]在 https://github.com/graphdeco-inria/gaussian-splatting/issues/762 中猜测CUDA代码中的旋转矩阵$R$与论文中的$R$并不是同一个, 是互逆的关系。 但是真的如此吗? 我们将CUDA代码中的R计算出来:
\[R = \begin{bmatrix} 1 - 2y^2 - 2z^2 & 2xy - 2rz & 2xz + 2ry \\ 2xy + 2rz & 1 - 2x^2 - 2z^2 & 2yz - 2rx \\ 2xz - 2ry & 2yz + 2rx & 1 - 2x^2 - 2y^2 \end{bmatrix} = 2 \begin{bmatrix} \frac{1}{2} - y^2 - z^2 & xy - rz & xz + ry \\ xy + rz & \frac{1}{2} - x^2 - z^2 & yz - rx \\ xz - ry & yz + rx & \frac{1}{2} - x^2 - y^2 \end{bmatrix}\]四元数为$(q_{r}, q_{i}, q_{j}, q_{k})$, 对应代码中的$r, x, y, z$ \(R = 2 \begin{bmatrix} \frac{1}{2} - q_{j}^2 - q_{k}^2 & q_{i}q_{j} - q_{r}q_{k} & q_{i}q_{k} + q_{r}q_{j} \\ q_{i}q_{j} + q_{r}q_{k} & \frac{1}{2} - q_{i}^2 - q_{k}^2 & q_{j}q_{k} - q_{r}q_{i} \\ q_{i}q_{k} - q_{r}q_{j} & q_{j}q_{k} + q_{r}q_{i} & \frac{1}{2} - q_{i}^2 - q_{j}^2 \end{bmatrix}\)
发现与论文附录中的公式10是完全相同的, 也就是说, 论文中的旋转矩阵和代码中的是相同的。
Q:$RSSR^T$与$R^TSSR$的值相同吗?
在回答这个问题前, 我们需要先思考另一个问题: 旋转和缩放是不是互不影响的?$RS==SR$是否成立?
在回答这个问题以前, 很容易忽略的一个问题是, 你这个所谓的”缩放”(scaling), 在空间的各个轴上是完全相同的吗? 换句话说: scaling矩阵$S$的对角线元素是否是完全相同的? 这影响着$R$和$S$是否可以交换顺序.
\[S = \begin{bmatrix} s_1 & 0 & 0 \\ 0 & s_2 & 0 \\ 0 & 0 & s_3 \end{bmatrix}\]先旋转 (R), 后缩放 (S)
一个向量 (v) 先旋转后缩放,然后 (S) 对旋转后的向量进行缩放。 [ v’ = SRv ] 这表示先通过 (R) 转换得到的矩阵(v),然后在这个新的状态下对这个矩阵进行 (S) 缩放。
先缩放 (S), 后旋转 (R)
(v) 先缩放,然后 (R) 对缩放后的向量进行旋转。 [ v’’ = RSv ] 这表示先在原始矩阵状态下进行缩放矩阵 (S) 缩放,然后 (R) 对缩放后的向量进行旋转。
CUDA代码中的参数scale是一个三维向量, 考虑一般的情况, 假设对角线元素$s_1, s_2, s_3$不是相同的, 那么两条路线的结果不同; 但是, 当对角线元素相同, 或者说更特殊的情况:没有进行缩放, 那么此时$RSSR^T$与$R^TSSR$的值就是相同的。
问题应该是出在: 关键词: 列主向量,
https://github.com/graphdeco-inria/gaussian-splatting/issues/100
Q:协方差矩阵是如何控制椭球的朝向的?
我们从物理的角度来思考,
使用RGBD序列初始化3dgs
为了能够使用深度相机得到的点云来代替colmap的结果,需要能够创建colmap的生成的三个文件。根据上文中对这些文件内容与相关读取/保存代码的分析,下面直接给出如何创建各个文件的结论。
使用read_extrinsics_binary和read_intrinsics_binary读取到的cameras_extrinsic_file与cameras_intrinsic_file都是字典类型, 其长度相同且key的值相同。
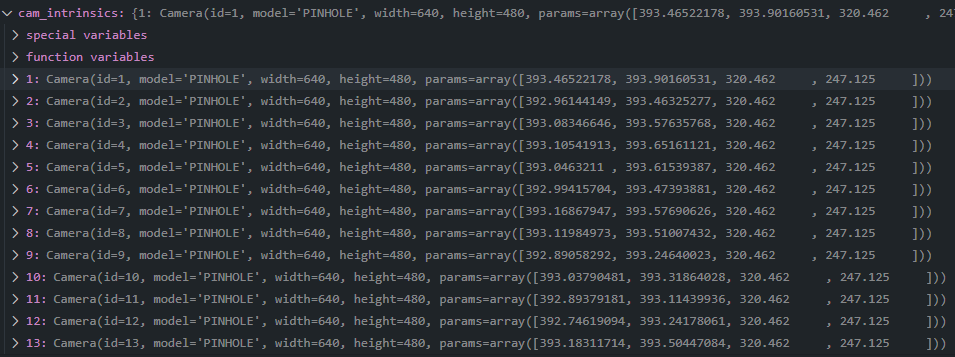
cameras.bin
dict中的每一项key对应的value都为一个scene.colmap_loader.Camera的实例, 记录相机类型、图像尺寸和相机内参等信息,可以生成一份之后,直接按图像的数量进行复制。
1
Camera(id=1, model='PINHOLE', width=640, height=480, params=array([393.465, 393.902, 320.462, 247.125]))
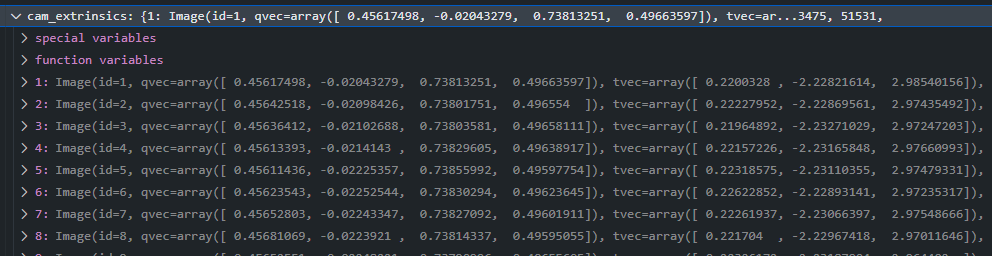
images.bin
相机的外部参数, dict中每一项为scene.colmap_loader.Image,其中记录了对应的图像文件名称, 表示相机外参的四元数与位移向量。
xys: 图像中特征点的二维坐标(需要注意其为浮点数), 分别表示x和y
point3D_ids:特征点在三维空间中的对应点的id, 用于将xys与三维点云建立映射关系。
1
2
3
4
5
6
7
Image
-id: 1
-name: '00000.png'
-qvec: numpy.ndarray, (4,)
-tvec: numpy.ndarray, (3,)
-xys: numpy.ndarray, (n, 2)
-point3D_ids: numpy.ndarray, (n,)
1
2
3
4
5
6
7
8
9
10
Image(id=1, qvec=array([ 0.45617498, -0.02043279, 0.73813251, 0.49663597]), tvec=array([ 0.2200328 , -2.22821614, 2.98540156]), camera_id=1, name='00000.png', xys=array([[475.42715454, 3.21835947],
[428.53314209, 5.41732264],
[428.53314209, 5.41732264],
...,
[291.12200928, 92.76355743],
[412.06417847, 319.75140381],
[412.06417847, 319.75140381]]),
point3D_ids=array([-1, -1, 52838, 51638, -1, 49220,
...,
51531, -1, 51681, 52214]))
point3D.bin
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
def readColmapCameras(cam_extrinsics, cam_intrinsics, images_folder):
cam_infos = []
for idx, key in enumerate(cam_extrinsics):
sys.stdout.write('\r')
# the exact output you're looking for:
sys.stdout.write("Reading camera {}/{}".format(idx+1, len(cam_extrinsics)))
sys.stdout.flush()
extr = cam_extrinsics[key]
intr = cam_intrinsics[extr.camera_id]
height = intr.height
width = intr.width
uid = intr.id
R = np.transpose(qvec2rotmat(extr.qvec))
T = np.array(extr.tvec)
if intr.model=="SIMPLE_PINHOLE":
focal_length_x = intr.params[0]
FovY = focal2fov(focal_length_x, height)
FovX = focal2fov(focal_length_x, width)
elif intr.model=="PINHOLE":
focal_length_x = intr.params[0]
focal_length_y = intr.params[1]
FovY = focal2fov(focal_length_y, height)
FovX = focal2fov(focal_length_x, width)
else:
assert False, "Colmap camera model not handled: only undistorted datasets (PINHOLE or SIMPLE_PINHOLE cameras) supported!"
image_path = os.path.join(images_folder, os.path.basename(extr.name))
image_name = os.path.basename(image_path).split(".")[0]
image = Image.open(image_path)
cam_info = CameraInfo(uid=uid, R=R, T=T, FovY=FovY, FovX=FovX, image=image,
image_path=image_path, image_name=image_name, width=width, height=height)
cam_infos.append(cam_info)
sys.stdout.write('\n')
return cam_infos
其中重要的有两点