:construction:施工中-6dgs阅读
代码复现
在Tanks&Temples和mip360上进行了测试
测试帧如下:
1
2
3
4
5
sequence_id: 2559653c-4, category_name: tt_Barn, frame range: 0 - 47
sequence_id: 7d4d7465-4, category_name: tt_Caterpillar, frame range: 0 - 45
sequence_id: 35905140-7, category_name: tt_Family, frame range: 0 - 18
sequence_id: 8c538952-3, category_name: tt_Ignatius, frame range: 0 - 32
sequence_id: 23edc6cc-7, category_name: tt_Truck, frame range: 0 - 31
1
2
3
4
5
6
7
sequence_id: 70cce534-5, category_name: mip_360_bicycle, frame range: 0 - 24
sequence_id: 993c8f78-2, category_name: mip_360_bonsai, frame range: 0 - 36
sequence_id: 8b5faada-0, category_name: mip_360_counter, frame range: 0 - 29
sequence_id: a986aed6-c, category_name: mip_360_garden, frame range: 0 - 23
sequence_id: aa65c3b8-7, category_name: mip_360_kitchen, frame range: 0 - 34
sequence_id: a03796be-7, category_name: mip_360_room, frame range: 0 - 38
sequence_id: a28bd2c5-4, category_name: mip_360_stump, frame range: 0 - 15
gt-camera
pred-camera
camera-corresponedence
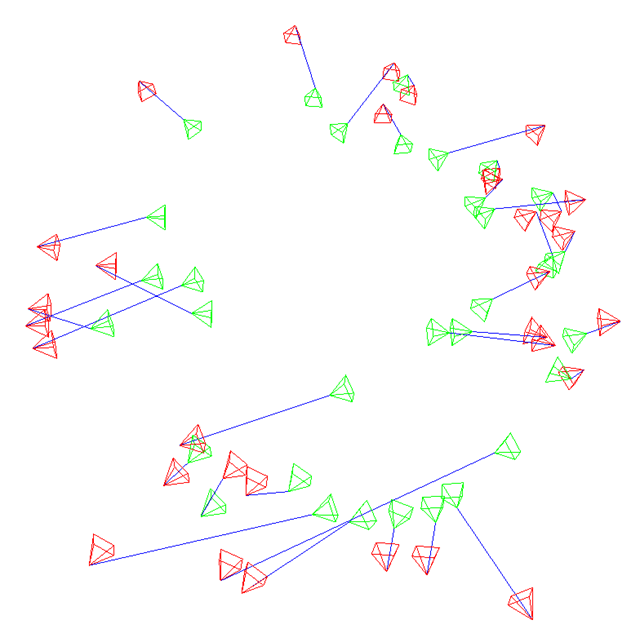
Tanks&Temples-Truck
假设条件:
输入: NVS模型(New View Synthesis)和目标图像(target image)
输出: target image在NVS模型坐标系下的相机姿态(camera pose)
iNeRF和6dgs都假设NVS模型是预先训练好的
分析-
文中提到了 conventional analysis-by-synthesis methodologies
指的是, 生成候选图像, 与真实目标图像比较, 优化模型参数(此处为相机姿态)的过程。
作者以iNeRF举例: 使用一个初始化的位姿pose来渲染一张图像(iteration #1), 将得到的图像与目标图像计算光度损失(photometric loss)并反向传播求导计算梯度,更新估计的位姿pose,指导最终的迭代结果(iteration #N)
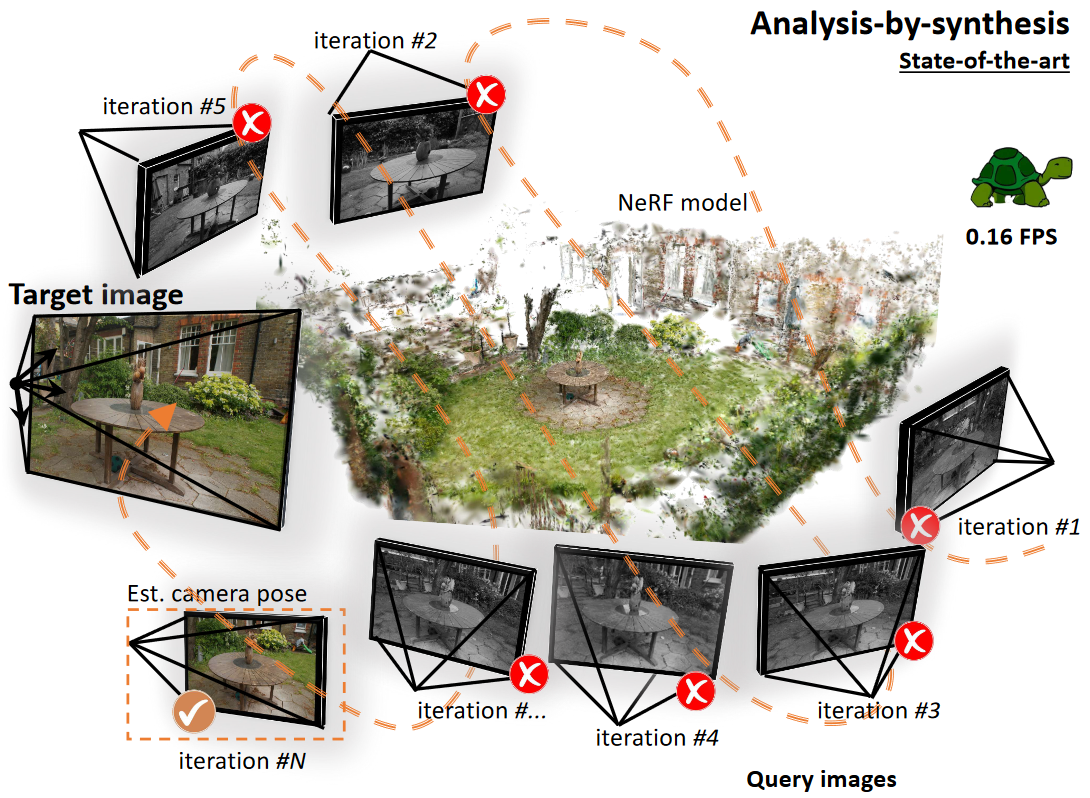
文中对比了部分NeRF-based方法, 如iNeRF. 这些方法渲染候选位姿, 对比渲染后的图像与目标图像, 然后更新相机位姿。 迭代此以上过程来实现位姿估计。作者认为这样精度和速度都会偏低。
如果已知相机位姿, 3DGS模型就能够渲染一张图像, 当然也能将所有的高斯椭球的中心点投影到图像的一个像素点上。
相机的光心(optical center)、图像像素点和高斯椭球的中心点可以被一条射线串起来。

而作者提出6dgs想反转这个过程。
因为目标图像对应的相机姿态是未知的,即相机的光心(位置)和朝向是未知的,就无法达成上面提到的三点一线。
作者为每个高斯椭球生成一组均匀分布的射线,尝试去优化得到相机的光心位置。
Ellicells
从生成的所有射线中, 挑选出能够与目标图像像素最匹配的一组射线
具体方法:attention map将图像像素与特定的射线进行绑定(无监督),根据相似性和空间对齐情况进行筛选。
当获得了bundle of rays后,计算加权最小二乘计算射线交点(权重来自相似性计算的置信度),来得到相机中心。
因为使用了无监督训练, 因此6dgs不需要初始位姿, 也避免了陷入局部极小值。