MUSt3R 论文阅读
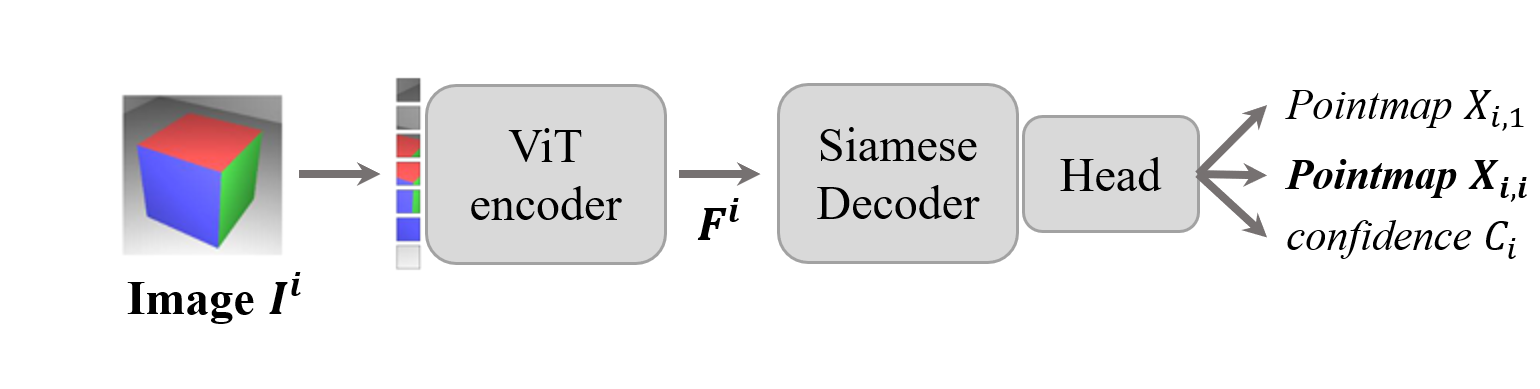
关于mast3r, dust3r, global alignment的一些理解
最近在kaggle上使用mast3r作为baseline, 遇到了一些disk溢出的问题
在sparse_global_alignment阶段, 会将所有的图像和图像对输入到forward_mast3r,计算对应关系,并将计算的结果缓存到cache目录下,之后的prepare_canonical_data阶段中会读取这些数据来归一化pointmap。
而缓存这一阶段,空间复杂度为$n^2$, 会导致缓存的文件非常多,但是应该还没有到溢出的问题,但是twin-input的缺陷已经开始显现了。
Q: MUSt3R是如何解决这个问题的?FAST3R, VGGT又是如何解决的?
Related work
Calibrated VO
缺乏深度信息会导致尺度模糊性(scale ambiguity)和深度模糊性(depth ambiguity), 因为相机的平移量t和场景的深度Z存在数学上的耦合关系。
因此,依赖RGB的SLAM系统智能恢复场景和相机运动的相对位姿,但是无法确定真实尺度。
而单目SLAM通过多帧图像匹配(特征点跟踪等)来估计深度,但是估计得到的相机深度依赖相机运动。
1.如果相机的运动是纯旋转,不包含位移,那么无法提供深度信息,因为像素的运动与深度是无关的。
2.仅包含平移的运动, 仍然需要有足够的视差(Parallax),小运动会导致视差不足,估计出的深度噪声很大。
低纹理区域和小运动幅度都会导致深度估计失效。
但是要空间还是要时间, 这就是另一个老生常谈的问题了, 只能具体问题具体分析。
本文由作者按照 CC BY 4.0 进行授权