VitT in MASt3r
[toc]
之前已经学习过了transformer, 现在更进一步,其在图形学领域的应用大名鼎鼎的ViT
MASt3r是如何应用ViT的,如果要拓展到其他工作, 应该如何使用它。
参考论文: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
参考代码: https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/vision_transformer.py
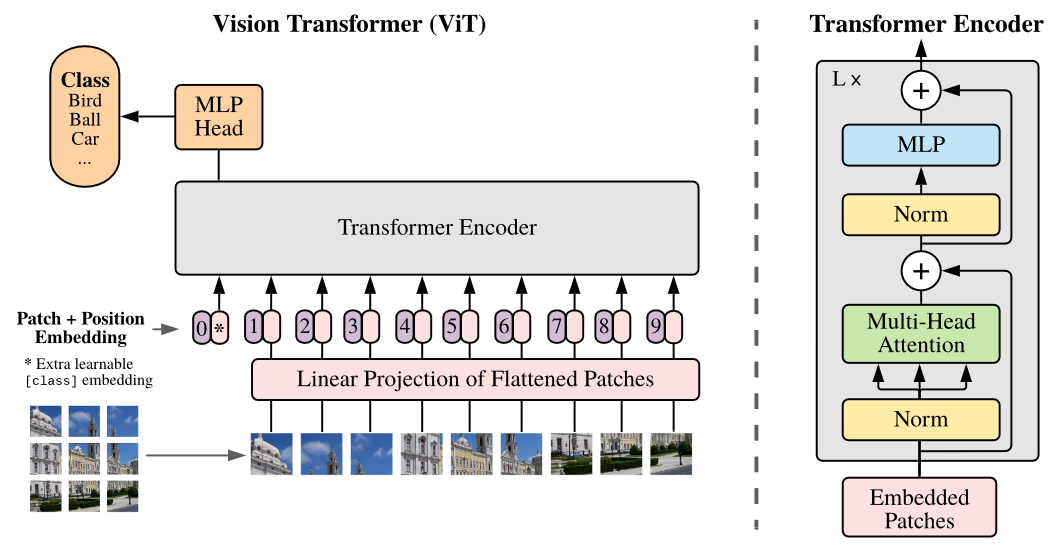
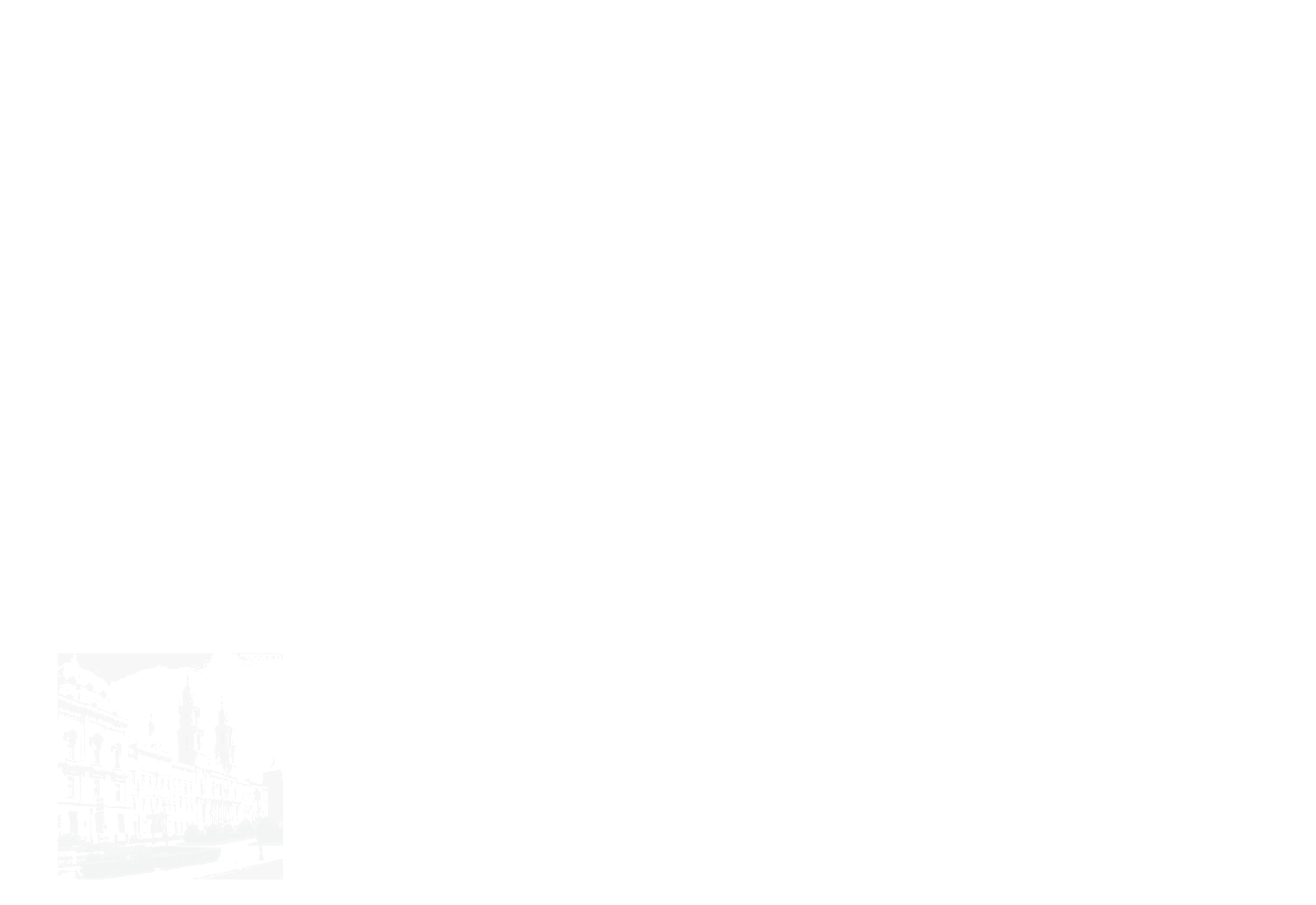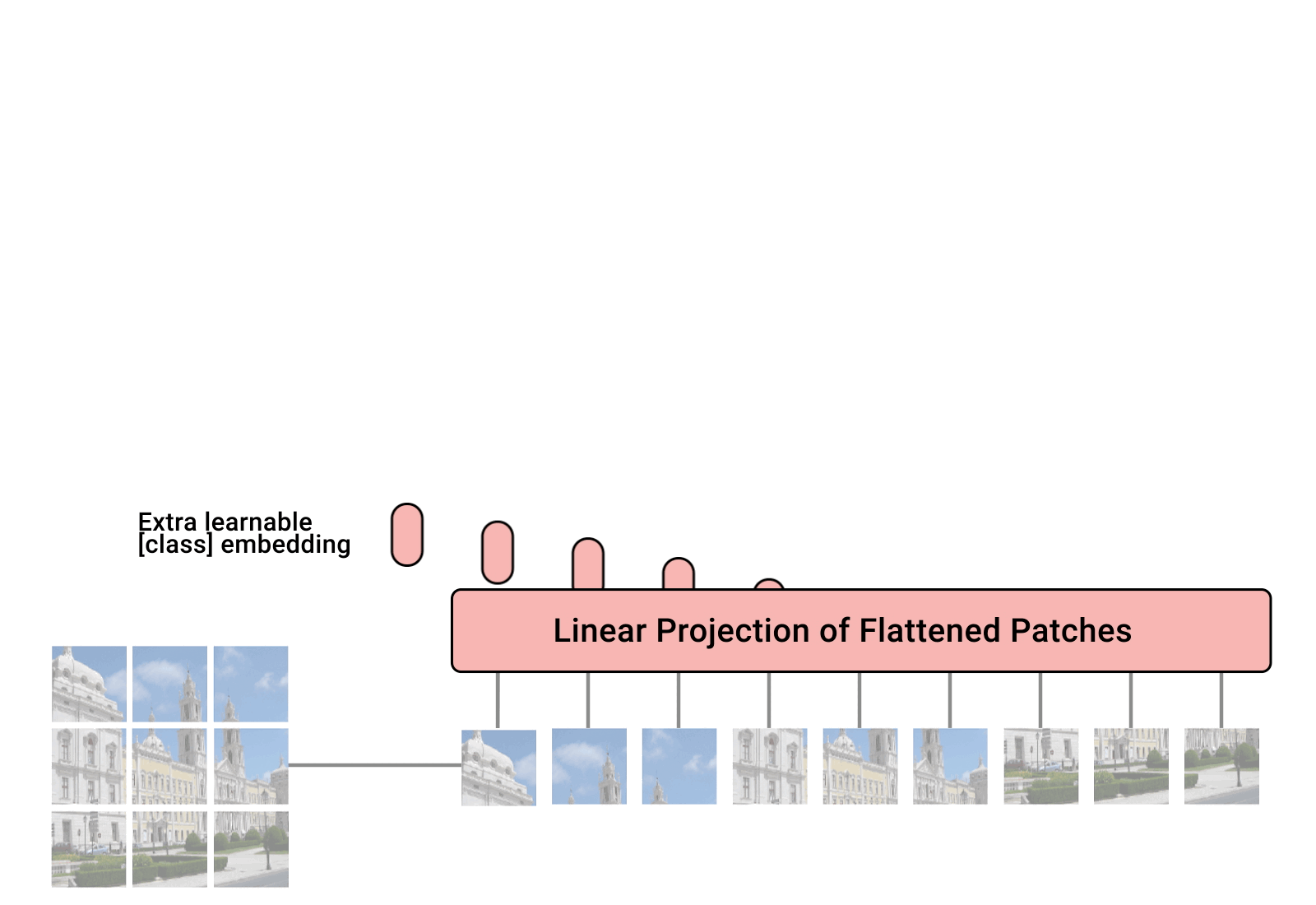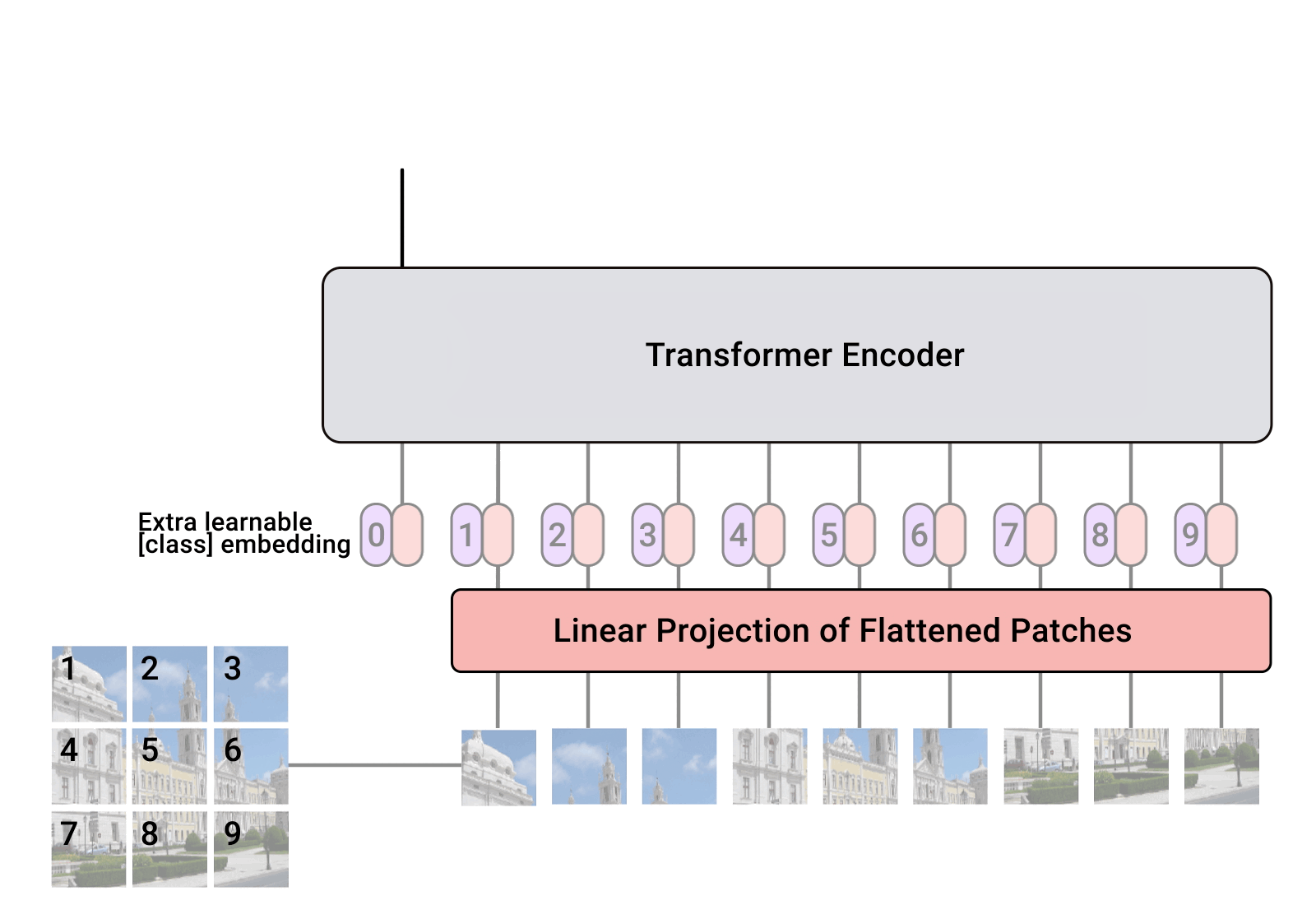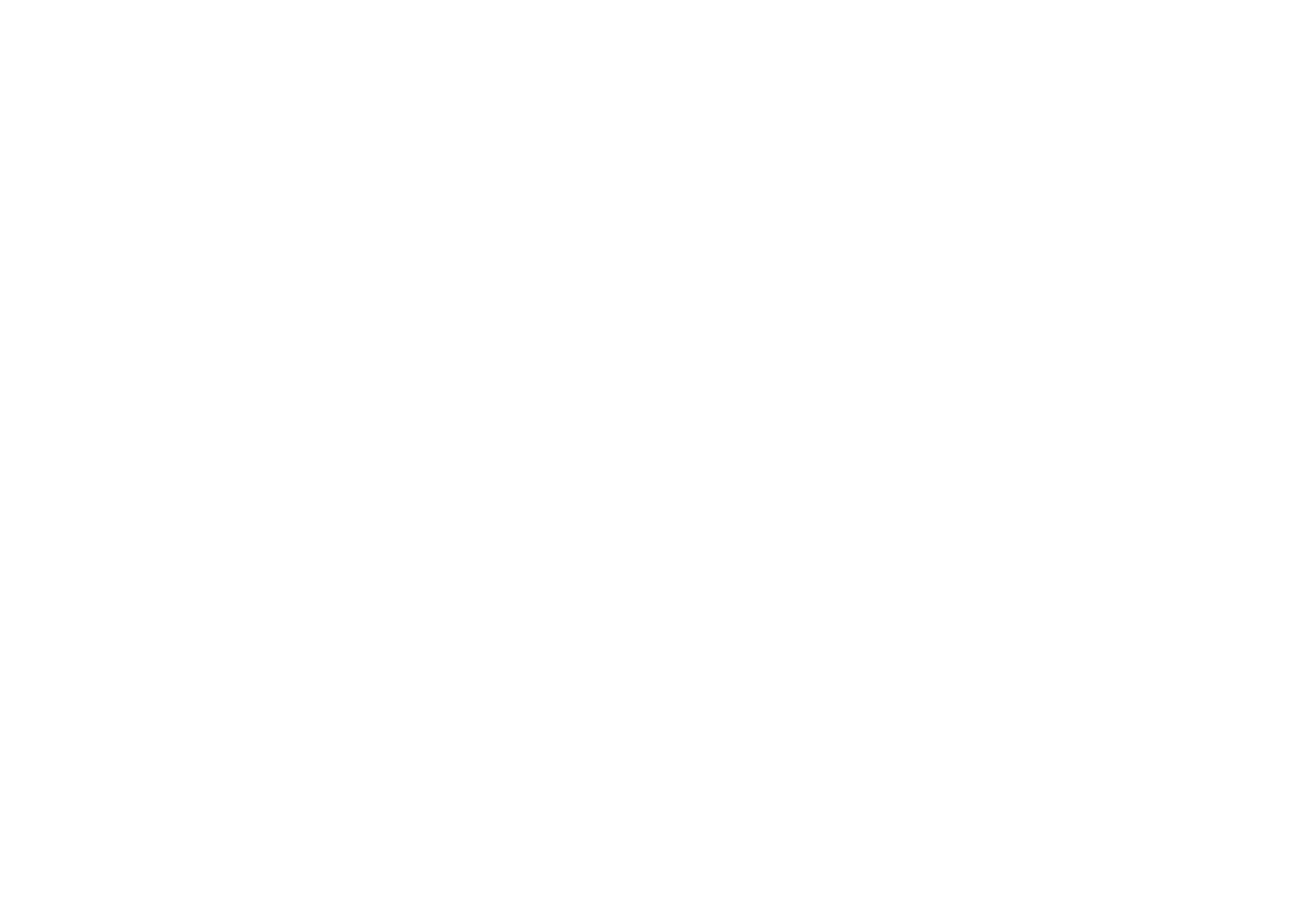
输入
ViT是由逐像素、2×2patch + self-attn发展演变而来的, 其初衷是为了匹配CNN。
transformer能够接受的输入是1D令牌形式
如图中所示: patch+position
输入图像-> 固定大小的patch, 计算图像的embedding和position embedding, 将结果的作为vector的序列输入到Transformer Encoder中, 图中为了执行分类任务, 还添加了额外的可学习的”classification token”.
输入的图像$x \in \R^{(H, W, C)}$, 分割为N个patch(代码中有缩放和裁剪等预处理操作, 保证图像的宽高能够被patch的尺寸整除), 图像被切分为$N$个patch, 表示为$x_p \in \R^{(N×(P^2 \cdot C))}$, $N=HW/P^2$
在dust3r/croco/models/blocks.py中有一个PatchEmb类, 其初始化使用了4个参数:
1
2
3
4
img_size: (512, 512)
patch_size: 16
in_channel: 3
enc_embed_dim: 1024
其中会计算新的属性:
1
2
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
其中grid_size其实就是计算H和W能被当前的patch分割为几份$(N_y, N_x)$, 并计算patch的数量num_patches也就是$N$
这个类还附带一个proj, 是一个nn.Conv2d, 输入维度为in_chans=3, 输出维度为embed_dim=1024, kernel_size=patch_size, 步长stride=patch_size. 所以这个proj其实就是对图像进行embed的操作。
norm则是一个归一化层, 负责对proj输出的结果进行归一化。如果初始化时指定了norm_layer则使用该layer, 如果没有指定则使用nn.Identity, 原样返回输入。
embedding
很多ViT的视线都会在输入阶段做一个小型的卷积或者线性投影来实现图像到token的转换(所谓的patch embedding), 例如LRM论文的framework中, 原始RGB图像经过Conv转换为token, 一般来说这个卷积/线性投影会被认为是ViT的一部分,但是也有论文像LRM一样会在绘制framework时将其与image encoder分开表述,了解这一点即可。
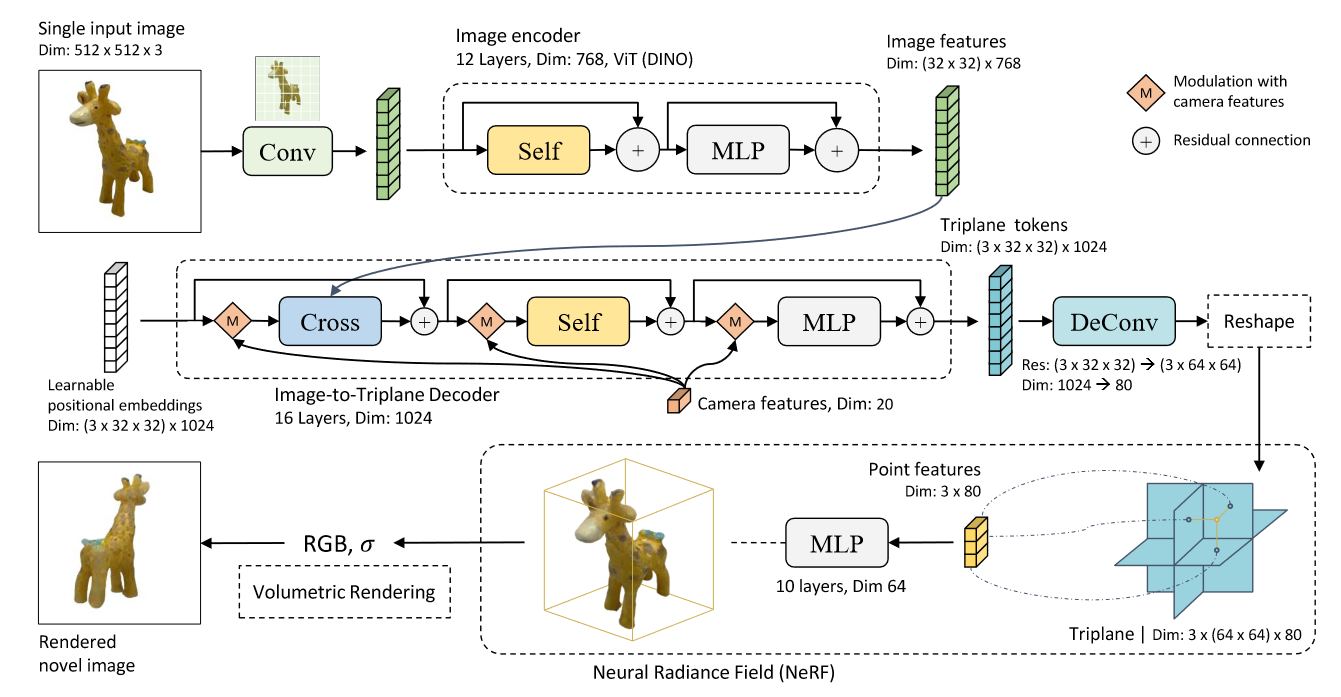
LRM: LARGE RECONSTRUCTION MODEL FOR SINGLE IMAGE TO 3D