MASt3r代码测试

[toc]
目标
尝试为mast3r添加mask支持, 仅mask中标记的前景区域参与匹配,生成对应关系。
代码部分
以下代码梳理和测试均以mast3r两帧图像match为例子
https://github.com/naver/mast3r?tab=readme-ov-file#usage
2-ImageMatchDemo
~~~ from mast3r.model import AsymmetricMASt3R from mast3r.fast_nn import fast_reciprocal_NNs import mast3r.utils.path_to_dust3r from dust3r.inference import inference from dust3r.utils.image import load_images if __name__ == '__main__': device = 'cuda' schedule = 'cosine' lr = 0.01 niter = 300 model_name = "naver/MASt3R_ViTLarge_BaseDecoder_512_catmlpdpt_metric" # you can put the path to a local checkpoint in model_name if needed model = AsymmetricMASt3R.from_pretrained(model_name).to(device) images = load_images(['dust3r/croco/assets/Chateau1.png', 'dust3r/croco/assets/Chateau2.png'], size=512) output = inference([tuple(images)], model, device, batch_size=1, verbose=False) # at this stage, you have the raw dust3r predictions view1, pred1 = output['view1'], output['pred1'] view2, pred2 = output['view2'], output['pred2'] desc1, desc2 = pred1['desc'].squeeze(0).detach(), pred2['desc'].squeeze(0).detach() # find 2D-2D matches between the two images matches_im0, matches_im1 = fast_reciprocal_NNs(desc1, desc2, subsample_or_initxy1=8, device=device, dist='dot', block_size=2**13) # ignore small border around the edge H0, W0 = view1['true_shape'][0] valid_matches_im0 = (matches_im0[:, 0] >= 3) & (matches_im0[:, 0] < int(W0) - 3) & ( matches_im0[:, 1] >= 3) & (matches_im0[:, 1] < int(H0) - 3) H1, W1 = view2['true_shape'][0] valid_matches_im1 = (matches_im1[:, 0] >= 3) & (matches_im1[:, 0] < int(W1) - 3) & ( matches_im1[:, 1] >= 3) & (matches_im1[:, 1] < int(H1) - 3) valid_matches = valid_matches_im0 & valid_matches_im1 matches_im0, matches_im1 = matches_im0[valid_matches], matches_im1[valid_matches] # visualize a few matches import numpy as np import torch import torchvision.transforms.functional from matplotlib import pyplot as pl n_viz = 20 num_matches = matches_im0.shape[0] match_idx_to_viz = np.round(np.linspace(0, num_matches - 1, n_viz)).astype(int) viz_matches_im0, viz_matches_im1 = matches_im0[match_idx_to_viz], matches_im1[match_idx_to_viz] image_mean = torch.as_tensor([0.5, 0.5, 0.5], device='cpu').reshape(1, 3, 1, 1) image_std = torch.as_tensor([0.5, 0.5, 0.5], device='cpu').reshape(1, 3, 1, 1) viz_imgs = [] for i, view in enumerate([view1, view2]): rgb_tensor = view['img'] * image_std + image_mean viz_imgs.append(rgb_tensor.squeeze(0).permute(1, 2, 0).cpu().numpy()) H0, W0, H1, W1 = *viz_imgs[0].shape[:2], *viz_imgs[1].shape[:2] img0 = np.pad(viz_imgs[0], ((0, max(H1 - H0, 0)), (0, 0), (0, 0)), 'constant', constant_values=0) img1 = np.pad(viz_imgs[1], ((0, max(H0 - H1, 0)), (0, 0), (0, 0)), 'constant', constant_values=0) img = np.concatenate((img0, img1), axis=1) pl.figure() pl.imshow(img) cmap = pl.get_cmap('jet') for i in range(n_viz): (x0, y0), (x1, y1) = viz_matches_im0[i].T, viz_matches_im1[i].T pl.plot([x0, x1 + W0], [y0, y1], '-+', color=cmap(i / (n_viz - 1)), scalex=False, scaley=False) pl.show(block=True) ~~~dust3r forward
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class AsymmetricCroCo3DStereo (
CroCoNet,
huggingface_hub.PyTorchModelHubMixin,
library_name="dust3r",
repo_url="https://github.com/naver/dust3r",
tags=["image-to-3d"],
):
""" Two siamese encoders, followed by two decoders.
The goal is to output 3d points directly, both images in view1's frame
(hence the asymmetry).
"""
...
def forward(self, view1, view2):
# encode the two images --> B,S,D
(shape1, shape2), (feat1, feat2), (pos1, pos2) = self._encode_symmetrized(view1, view2)
# combine all ref images into object-centric representation
dec1, dec2 = self._decoder(feat1, pos1, feat2, pos2)
with torch.cuda.amp.autocast(enabled=False):
res1 = self._downstream_head(1, [tok.float() for tok in dec1], shape1)
res2 = self._downstream_head(2, [tok.float() for tok in dec2], shape2)
res2['pts3d_in_other_view'] = res2.pop('pts3d') # predict view2's pts3d in view1's frame
return res1, res2
view1, view2是dict类型, 包含4个key: img, true_shape, idx, instance
在输入到dust3r.forward之前已经经过了尺度缩放(默认缩放到最长边为512), 移动img到指定设备(gpu)上。
_encode_symmetrized获取两个视角的img图像(Batch_size, Channel, Width, Height), 获取true_shape, torch.Size([1, 2])存储着图像的Width和Height.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def _encode_symmetrized(self, view1, view2):
img1 = view1['img']
img2 = view2['img']
B = img1.shape[0]
# Recover true_shape when available, otherwise assume that the img shape is the true one
# 尝试获取true_shape, 如果没有则使用当前的图像大小作为true_shape
shape1 = view1.get('true_shape', torch.tensor(img1.shape[-2:])[None].repeat(B, 1))
shape2 = view2.get('true_shape', torch.tensor(img2.shape[-2:])[None].repeat(B, 1))
# warning! maybe the images have different portrait/landscape orientations
if is_symmetrized(view1, view2):
# computing half of forward pass!'
feat1, feat2, pos1, pos2 = self._encode_image_pairs(img1[::2], img2[::2], shape1[::2], shape2[::2])
feat1, feat2 = interleave(feat1, feat2)
pos1, pos2 = interleave(pos1, pos2)
else:
feat1, feat2, pos1, pos2 = self._encode_image_pairs(img1, img2, shape1, shape2)
return (shape1, shape2), (feat1, feat2), (pos1, pos2)
编码图像对
PatchEmbed
可以看到, 编码图像对时有两种:
但是这两种不同只在于forward函数, 其都继承自croco的PatchEmbed类。
ViT的encoder部分其实很简单, 在model.py中匆匆一行
1
(shape1, shape2), (feat1, feat2), (pos1, pos2) = self._encode_symmetrized(view1, view2)
对应到model.py中
1
2
3
4
5
6
7
8
9
10
11
12
13
def _encode_image(self, image, true_shape):
# embed the image into patches (x has size B x Npatches x C)
x, pos = self.patch_embed(image, true_shape=true_shape)
# add positional embedding without cls token
assert self.enc_pos_embed is None
# now apply the transformer encoder and normalization
for blk in self.enc_blocks:
x = blk(x, pos)
x = self.enc_norm(x)
return x, pos, None
首先patch_embed输入图像进行编码, 输出特征x和位置编码pos
以PatchEmbedDust3R为例子,
1
2
3
4
5
6
7
8
9
10
11
class PatchEmbedDust3R(PatchEmbed):
def forward(self, x, **kw):
B, C, H, W = x.shape # 确保图像的长宽能够被patch size整除
assert H % self.patch_size[0] == 0, f"Input image height ({H}) is not a multiple of patch size ({self.patch_size[0]})."
assert W % self.patch_size[1] == 0, f"Input image width ({W}) is not a multiple of patch size ({self.patch_size[1]})."
x = self.proj(x)
pos = self.position_getter(B, x.size(2), x.size(3), x.device)
if self.flatten:
x = x.flatten(2).transpose(1, 2) # BCHW -> BNC
x = self.norm(x)
return x, pos
可以看到, 输入的图像以patch的大小为步长提取特征, PositionGetter负责获得每个patch对应的位置。
1
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
提取到特征之后, x的shape从(B, C, H, W)变为$(B, C_{embed}, H_p, W_p)$, 其中的$H_p$和$W_p$都是patch在纵横方向的数量。$H_p=(H-P)//P+1$, $W_p=(W-P)//P+1$
将后两维度输入到PositionGetter中, 可以得到patch所在的位置。
1
2
self.position_getter = PositionGetter()
pos = self.position_getter(B, x.size(2), x.size(3), x.device)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
...
# patch embedding
class PositionGetter(object):
""" return positions of patches """
def __init__(self):
self.cache_positions = {}
def __call__(self, b, h, w, device):
if not (h,w) in self.cache_positions:
x = torch.arange(w, device=device)
y = torch.arange(h, device=device)
self.cache_positions[h,w] = torch.cartesian_prod(y, x) # (h, w, 2)
pos = self.cache_positions[h,w].view(1, h*w, 2).expand(b, -1, 2).clone()
return pos
所以PatchEmbedDust3R其实就做了按Patch提取特征x和计算位置pos这么个事情。
encoder blocks
但是提取特征后, encode阶段其实还没有完成。我们可以发现有x = blk(x, pos)这么一步
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class AsymmetricCroCo3DStereo
...
def _encode_image(self, image, true_shape):
# embed the image into patches (x has size B x Npatches x C)
x, pos = self.patch_embed(image, true_shape=true_shape)
# add positional embedding without cls token
assert self.enc_pos_embed is None
# now apply the transformer encoder and normalization
for blk in self.enc_blocks:
x = blk(x, pos)
x = self.enc_norm(x)
return x, pos, None
这段代码来自croco, 也就是dust3r论文中提到的.
1
2
3
self.enc_blocks = nn.ModuleList([
Block(enc_embed_dim, enc_num_heads, mlp_ratio, qkv_bias=True, norm_layer=norm_layer, rope=self.rope)
for i in range(enc_depth)])
rope是指(Relative Positional Encoding)相对位置编码。每一个Block就是attention+MLP, 默认的enc_depth=12, 也就是叠了12层Block.
所以结构其实很简单
1
2
3
4
5
input: img
encoder(Patch embed) -> x, pos
x, pos -> self-attn -> x
norm(x) -> linear -> qkv
linear(attn(qkv)) -> x
对称
在encoder中处处有对对称情况的处理, 一切的判断都来自函数
1
is_symmetrized(view1, view2)
那么什么情况才会被判定位两个view是对称的? 我们检查其位于misc.py的代码可以发现,对称其实检查的是view的instance项 检查相邻的元素是否”成对,对称互换”, 期待的对称情况是两个view的instance满足[a,b,c,d]和[b,a,d,c]. 即步长为2, 每两个, 都是互换的a,b和b,a、c,d和d,c
Transformer Decoder
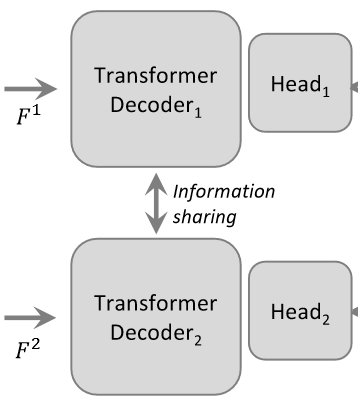
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# transfer from encoder to decoder
self.decoder_embed = nn.Linear(enc_embed_dim, dec_embed_dim, bias=True)
# transformer for the decoder
self.dec_blocks = nn.ModuleList(
[
DecoderBlock(
dec_embed_dim,
dec_num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=True,
norm_layer=norm_layer,
norm_mem=norm_im2_in_dec,
rope=self.rope)
for i in range(dec_depth)
]
)
decoder_embed做了一个简单的线性变换,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def _decoder(self, f1, pos1, f2, pos2):
final_output = [(f1, f2)] # before projection
# project to decoder dim
f1 = self.decoder_embed(f1)
f2 = self.decoder_embed(f2)
final_output.append((f1, f2))
for blk1, blk2 in zip(self.dec_blocks, self.dec_blocks2):
# img1 side
f1, _ = blk1(*final_output[-1][::+1], pos1, pos2)
# img2 side
f2, _ = blk2(*final_output[-1][::-1], pos2, pos1)
# store the result
final_output.append((f1, f2))
# normalize last output
del final_output[1] # duplicate with final_output[0]
final_output[-1] = tuple(map(self.dec_norm, final_output[-1]))
return zip(*final_output)
1
2
3
4
input: img
x1, pos1 -> self-attn -> x1
x1, pos1, x2, pos2 -> cross-attn -> x1
x1 -> MLP
GlobalAligner
view1, view2, pred1, pred2之间的关系是什么?
model的输入输出为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
输入:
view1, view2
img, (B, C, H, W)
true_shape, (B, 2) 每个Batch存储[H,W]
idx, list, len==B, 存储两个图像的idx
instance, list, len==B, 存储对应idx的字符类型
例子:
images = load_images([img_path_1, img_path_2], size=512) # 加载两张图像
# 图像分别为images[0]['img'], images[1]['img']
view1
img: (2, 3, 512, 288)
true_shape: [[512, 288], [512, 288]]
idx: [1, 0]
instance: ['1', '0']
view2
img: (2, 3, 512, 288)
true_shape: [[512, 288], [512, 288]]
idx: [0, 1]
instance: ['0', '1']
# 验证 torch.all(images[1]['img'][0] == view2['img'][1])
# view1, view2中的idx对应着load_images中的图像的下标,
# 例如view1['idx']为[1, 0], 那么view1['img'][0]的idx就是1, 对应的图像就是images[1]['img'];
# 同理, view1['img'][1]对应的idx为0, 对应images[0]['img']
# 可通过代码 torch.all(images[0]['img'][0] == view1['img'][1])
# 进行验证
输出:
view1, view2
pred1,
pts3d, conf, desc, desc_conf
pred2
pts3d_in_other_view, conf, desc, desc_conf
loss(使用时为None)
观察training.py中的loss,
1
2
3
ConfLoss(Regr3D(L21, norm_mode='avg_dis'), alpha=0.2)
((loss1, msk1), (loss2, msk2)), details = self.pixel_loss(gt1, gt2, pred1, pred2, **kw)
先看Regr3D, 获取了gt1[‘camera_pose’], 并计算相机的逆, 将gt1和gt2的pts3d变换到相机1坐标系下, 以view1作为锚点。(也就是说, 原本gt1[‘pts3d’]和gt2[‘pts3d’]都是在世界坐标系下的, 通过相机1相机位姿的逆变换, 变为相机1坐标系下)
注意训练过程中的虽然输入的也是view1和view2, 但是此时的view其实是作为gt的, 其中包含了ground-truth信息, 比如世界坐标系下的点云pts3d, 相机位姿camera_pose, 场景的遮罩valid_mask.
get_pred_pts3d函数主要包含两部分内容, 第一部分, 获得当前相机的view下的点云。 如果pred1中有深度和相机内参, 则使用反投影直接得到pts3d; 如果只有pred[‘pts3d’], 则直接使用;
由于输出的是pointmap, 所以我们可以把它当做一个深度图来直接进行可视化(仅可视化z)

添加conf_mask后的结果, 从左到右分别是对conf<1.0, conf<1.05, conf<1.10, conf<1.15, conf<1.2的过滤结果

但是conf其实是相互的, 应当根据双向的conf来过滤, 哪些点来计算
如果use_pose为true, 使用pred.get(‘camera_pose’)获得估计得到的当前的相机的位姿, 使用该位姿对得到的点云进行转换。下面的代码, pred1的点云直接使用pts3d, pred2的点云则是使用camera_pose对pts3d进行转换。
1
2
pr_pts1 = get_pred_pts3d(gt1, pred1, use_pose=False)
pr_pts2 = get_pred_pts3d(gt2, pred2, use_pose=True)
camera_pose == 相机坐标系到世界坐标系的变换$T_{wc}$, in_camera1则是世界坐标系到相机坐标系的变换。因此, gt_pts1和gt_pts2是在相机坐标系下的点云, gt1[‘pts3d’]和gt2[‘pts3d’]是世界坐标系下的点云。
1
in_camera1 = inv(gt1['camera_pose'])
1
2
gt_pts1 = geotrf(in_camera1, gt1['pts3d']) # B,H,W,3
gt_pts2 = geotrf(in_camera1, gt2['pts3d']) # B,H,W,3
在返回的结果中, pr_pts1与gt_pts1计算loss, pr_pts2与gt_pts2计算loss, 说明pr_pts1和pr_pts2都是在相机1坐标系下的点云, 说明pred1[‘pts3d’]是在相机1坐标系下的点云, pred2[‘pts3d’]是在相机2坐标系下的点云, pred2[‘camera_pose’]则是相机2->相机1的变换。
根据ConfLoss的计算loss的代码, 可以确认pred1[‘conf’]对应的是img1, pred2[‘conf’]对应的是img2
1
2
3
4
5
# weight by confidence
conf1, log_conf1 = self.get_conf_log(pred1['conf'][msk1])
conf2, log_conf2 = self.get_conf_log(pred2['conf'][msk2])
conf_loss1 = loss1 * conf1 - self.alpha * log_conf1 # conf_1*loss_1 - alpha*log(conf_1)
conf_loss2 = loss2 * conf2 - self.alpha * log_conf2
Q: 但是mast3r中的输出中的pts3d_in_other_view又是哪里来的?
A: 来自AsymmetricCroCo3DStereo, 也就是mast3r模型AsymmetricMASt3R的父类
pts3d_in_other_view其实就是res2的pts3d, 注释也写明白了, 是预测的view2的点云, 但是在view1的坐标系下。
1
2
3
4
5
6
7
8
9
10
11
12
13
def forward(self, view1, view2):
# encode the two images --> B,S,D
(shape1, shape2), (feat1, feat2), (pos1, pos2) = self._encode_symmetrized(view1, view2) # 对图像中的patch encode
# combine all ref images into object-centric representation
dec1, dec2 = self._decoder(feat1, pos1, feat2, pos2)
with torch.cuda.amp.autocast(enabled=False):
res1 = self._downstream_head(1, [tok.float() for tok in dec1], shape1)
res2 = self._downstream_head(2, [tok.float() for tok in dec2], shape2)
res2['pts3d_in_other_view'] = res2.pop('pts3d') # predict view2's pts3d in view1's frame
return res1, res2
所以我们可以得出结论:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
输入:
view1, view2
img, (B, C, H, W)
true_shape, (B, 2) 每个Batch存储[H,W]
idx, list, len==B, 存储两个图像的idx
instance, list, len==B, 存储对应idx的字符类型
输出:
view1, view2
pred1,
pts3d, view1[idx][0]在view1的点云, view1[idx][1]在view1的点云
conf,
desc,
desc_conf
pred2
pts3d_in_other_view, view2[idx][0]在view1[idx][0]坐标系下的点云, view2[idx][1]在view1[idx][1]坐标系下的点云
conf,
desc,
desc_conf
loss(使用时为None)

从左到右为 ['pred1']['pts3d'][0], ['pred2']['pts3d_in_other_view'][0], ['pred1']['pts3d'][1], ['pred2']['pts3d_in_other_view'][1]
上面的结果我们按batch分别观察, [0]和[1]其实是区分不同的batch, 我们首先看batch0:
[‘pred1’][‘pts3d’][0]对应着view1中batch0的图像, view1[idx][0], 即图像1, 图像1的点云在图像1坐标系下。
[‘pred2’][‘pts3d_in_other_view’][0]则是view2[idx][0], 即图像0的点云在图像1坐标系下。
到这里其实隐约能够感觉到, 为什么要使用make_pair将图像对进行交换, 是为了确保图像即便交换顺序也不会因为encoder-decoder而得到不同的结果。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
例子:
images = load_images([img_path_1, img_path_2], size=512) # 加载两张图像
# 图像分别为images[0]['img'], images[1]['img']
view1
img: (2, 3, 512, 288)
true_shape: [[512, 288], [512, 288]]
idx: [1, 0]
instance: ['1', '0']
view2
img: (2, 3, 512, 288)
true_shape: [[512, 288], [512, 288]]
idx: [0, 1]
instance: ['0', '1']
# 验证 torch.all(images[1]['img'][0] == view2['img'][1])
输出的图像, 输出的pointmap(pts3d和pts3d_in_other_view)的对应以及所在坐标系如下图所示:

merge_corres
将nn得到的对应关系进行合并
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
def merge_corres(idx1, idx2, shape1=None, shape2=None, ret_xy=True, ret_index=False):
assert idx1.dtype == idx2.dtype == np.int32
# unique and sort along idx1
# np.c_ 沿列方向拼接idx2, idx1
# ret_index为True会返回唯一值首次出现的索引
corres = np.unique(np.c_[idx2, idx1].view(np.int64), return_index=ret_index)
if ret_index:
corres, indices = corres
xy2, xy1 = corres[:, None].view(np.int32).T
if ret_xy:
assert shape1 and shape2
xy1 = np.unravel_index(xy1, shape1)
xy2 = np.unravel_index(xy2, shape2)
if ret_xy != 'y_x':
xy1 = xy1[0].base[:, ::-1]
xy2 = xy2[0].base[:, ::-1]
if ret_index:
return xy1, xy2, indices
return xy1, xy2
idx2和idx1的shape为(n,), np.c_拼接后的shape为(n, 2), 即拼接为了n个对,使用view(np.int64)将n个对转换为n个64位整数,从而可以使np.unique函数找到唯一的(idx2, idx1)对。
1
xy2, xy1 = corres[:, None].view(np.int32).T
先试用corres[:, None]增加一个维度变为(n, 1),然后转换回”对”, 形状为(n, 2)。转置变为(2, n)的形式。xy2和xy1得到的是(n, )形状的坐标。
np.unravel_idx将xy1变形为shape1的形状,xy2同理。
view会将每个对解释为np.int64, 同时会按idx1排序
如果np.unique中的return_index=True, 那么还会返回排序前的index
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
>>> import numpy as np
>>> l1 = np.array([1,1,2,2,3],dtype=np.int32)
>>> l2 = np.array([2,1,2,1,4],dtype=np.int32)
>>> np.c_[l1, l2]
array([[1, 2],
[1, 1],
[2, 2],
[2, 1],
[3, 4]], dtype=int32)
>>> np.c_[l1, l2].view(np.int64)
array([[ 8589934593],
[ 4294967297],
[ 8589934594],
[ 4294967298],
[17179869187]])
>>> np.unique(np.c_[l1, l2].view(np.int64))
array([ 4294967297, 4294967298, 8589934593, 8589934594, 17179869187])
>>> np.unique(np.c_[l1, l2].view(np.int64), return_index=True)
(array([ 4294967297, 4294967298, 8589934593, 8589934594, 17179869187]), array([1, 3, 0, 2, 4]))
>>> np.unique(np.c_[l1, l2].view(np.int64))[:,None].view(np.int32)
array([[1, 1],
[2, 1],
[1, 2],
[2, 2],
[3, 4]], dtype=int32)
X12, X11, X
对比
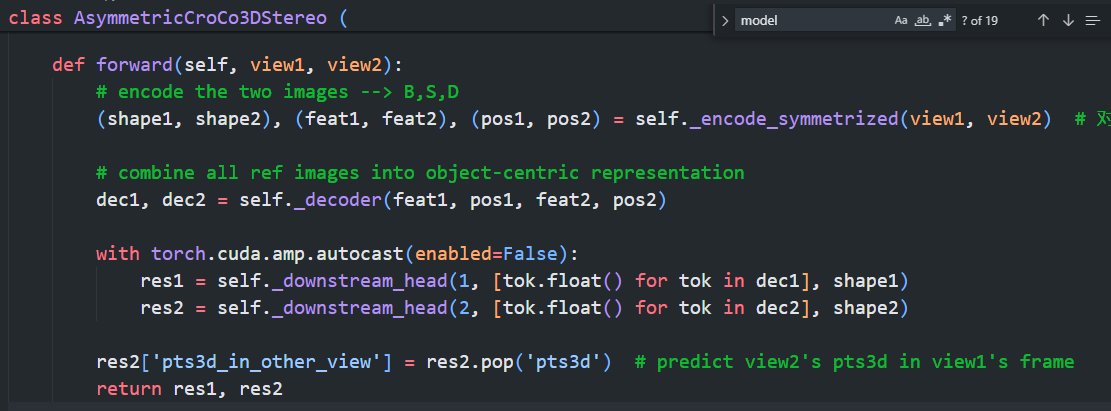
上图为mast3r, github-README中的简单demo中的模型推理部分代码
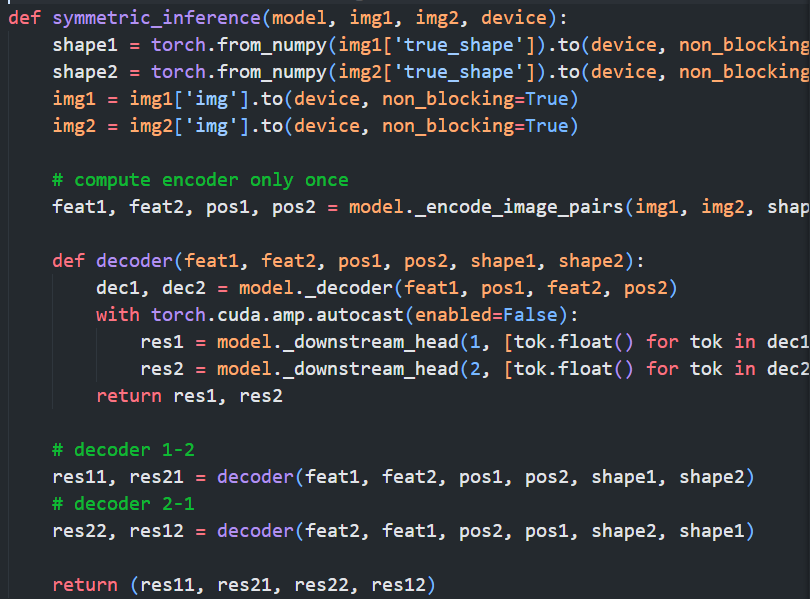
上图为mast3r, interactive demo中的简单demo中的模型推理部分代码
可以看到, 进行的操作其实都是一样的, 我们也可以找到映射关系
可以看到, README-demo和Interactive-demo都是同样的输入
1
dec1, dec2 = self._decoder(feat1, pos1, feat2, pos2)
但是Interactive-demo选择将decoder进行封装
1
2
3
4
5
6
def decoder(feat1, feat2, pos1, pos2, shape1, shape2):
dec1, dec2 = model._decoder(feat1, pos1, feat2, pos2)
with torch.cuda.amp.autocast(enabled=False):
res1 = model._downstream_head(1, [tok.float() for tok in dec1], shape1)
res2 = model._downstream_head(2, [tok.float() for tok in dec2], shape2)
return res1, res2
并且交换了feat1和feat2等输入,相当于处理了两次。这也是为什么它称为symmetric_inference. 这是它与AsymmetricCroCo3DStereo中forward唯一的区别。
但是实际上, README-demo中的inference其实在生成pairs的时候就把对称的对给生成的, 因此最终也能得到对称的情况。
1
2
3
4
5
def inference(pairs, model, device, batch_size=8, verbose=True):
...
for i in tqdm.trange(0, len(pairs), batch_size, disable=not verbose):
res = loss_of_one_batch(collate_with_cat(pairs[i:i + batch_size]), model, None, device) # collate_with_cat对于list输入[[img1, img2], [img2, img3]]->[img1, img2, img3, img4]
result.append(to_cpu(res))
因此, 对于同样的一个pairs(假设为<img1, img2>), README-demo返回的结果res1与Interactive-demo中的res11, res21是相同的(res22, res12与README-demo的另一对<img2, img1>的结果对应)。
还需要注意: README-demo中, 将res2的pts3d改了个名字:
1
res2['pts3d_in_other_view'] = res2.pop('pts3d')
| – | README-demo | Interactive-demo |
|---|---|---|
| return | res1, res2 | res11, res21, res22, res12 |
但是事实上, make_pairs时(images中的所有图像, 被处理为pairs时), symmetrize=True就会生成对称的图像对, 但是顺序是不能保证的:
1
2
3
4
pairs = make_pairs(images, scene_graph='complete', prefilter=None, symmetrize=True)
>>> [(p[0]['idx'], p[1]['idx'])for p in pairs]
[(1, 0), (2, 0), (2, 1), (0, 1), (0, 2), (1, 2)]
1
2
3
4
5
>>> output['view1']['idx']
[1, 2, 2, 0, 0, 1]
>>> output['view2']['idx']
[0, 0, 1, 1, 2, 2]
因此之后寻找对称的对是个问题,这可能也是使用symmetric_inference的原因。
当然这个也很好解决, 只需要修改make_pairs函数中生成对称的部分, 就能确保对称的部分总是相邻的:
1
2
3
4
5
6
--- pairs += [(img2, img1) for img1, img2 in pairs]
+++ new_pairs = []
+++ for img1, img2 in pairs:
+++ new_pairs.append((img1, img2)) # 添加原始元组
+++ new_pairs.append((img2, img1)) # 添加对称元组
+++ pairs = new_pairs
anchor_depth_offsets
计算图像中像素点相对于锚点的深度偏移。具体来说,它会在给定的深度图 canon_depth 上创建一个二维网格的锚点,返回:
core_idxs, (生成自)对应点点在二维网格上对应的锚点
core_offs, 对应点与锚点的深度比
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
canon_depth:一个二维的深度图。
pixels:dict, 包含图像中的像素点及其对应的置信度。
subsample:int, 定义锚点的间隔。
def anchor_depth_offsets(canon_depth, pixels, subsample=8):
device = canon_depth.device
# create a 2D grid of anchor 3D points
# 创建一个二维的网格, 按subsample的间隔取点
H1, W1 = canon_depth.shape
yx = np.mgrid[subsample // 2:H1:subsample, subsample // 2:W1:subsample] # 返回(2, H_n, W_n), 第1个维度区分高/宽, 第2个维度对应高度方向的坐标, 第3个维度对应宽度方向的坐标
H2, W2 = yx.shape[1:]
cy, cx = yx.reshape(2, -1) # 转换锚点的坐标为 -> (H_n, W_n) H_n为高度方向的坐标数, W_n为宽度方向的坐标数
core_depth = canon_depth[cy, cx] # (n, ) n==len(cy)==len(cx), 从深度图中取出锚点的深度
assert (core_depth > 0).all() # 确保所有锚点的深度都是正数(不会在相机背面/深度缺失)
# >>> b2 = np.mgrid[subsample // 2:H:subsample, subsample // 2:W:subsample].reshape(2,-1)
# array([[ 4, 4, 4, 4, 12, 12, 12, 12],
# [ 4, 12, 20, 28, 4, 12, 20, 28]])
# >>> cy
# array([ 4, 4, 4, 4, 12, 12, 12, 12])
# >>> cx
# array([ 4, 12, 20, 28, 4, 12, 20, 28])
# slave 3d points (attached to core 3d points)
core_idxs = {} # core_idxs[img2] = {corr_idx:core_idx}
core_offs = {} # core_offs[img2] = {corr_idx:3d_offset}
for img2, (xy1, _confs) in pixels.items():
px, py = xy1.long().T # 获取当前图像的对应点的坐标
# find nearest anchor == block quantization
core_idx = (py // subsample) * W2 + (px // subsample) # 计算对应点的锚点的索引core_idx
core_idxs[img2] = core_idx.to(device) # 保存到core_idxs中, 使用另一个img的index作为key
# compute relative depth offsets w.r.t. anchors
ref_z = core_depth[core_idx] # 获取锚点的深度
pts_z = canon_depth[py, px]
offset = pts_z / ref_z # 对应点深度到锚点深度的比值
core_offs[img2] = offset.detach().to(device)
return core_idxs, core_offs # 返回对应点的锚点索引与相对于锚点的深度偏移
anchor_depth_offsets是仅针对当前图像的, 他不控制图像之间的关系, 仅对当前输入的一张相对深度图(canon2)进行处理。
返回的是:
core_idxs: 每个像素点的最近锚点的索引
core_offs: 像素点与其锚点之间的相对深度比 (offset = pts_z / ref_z 计算得到的)
anchor的结构
anchor是在condense_data函数中生成的。在condense_data中,计算的数据基本都来源与canonical_views中。
1
2
3
4
5
def condense_data(imgs, tmp_paths, canonical_views, preds_21, dtype=torch.float32):
...
for idx1, img1 in enumerate(imgs): # 遍历所有图像
pp, shape, focal, anchors, pixels_confs, idxs, offsets = canonical_views[img1]
canonical_views针对每张图像img有一个key, value中的offsets, idxs, pixels_confs等, 其key都是当前图像img构成pair的其他图像
1
2
3
4
5
6
7
canonical_views:dict
|----key:img1:str
|----value:offsets:dict
|----key:img2:str
|----value:tensor ...
|----key:img3:str
...
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
for idx1, img1 in enumerate(imgs): # 遍历所有图像
img_uv1 = []
img_idxs = []
img_offs = []
cur_n = [0]
# pixels[img2] = xy1, confs # img1的pixel中存储了所有成对的对应图像img2, 其对应的当前图像的像素点xy1和置信度confs
for img2, (pixels, match_confs) in pixels_confs.items():
...
img_uv1.append(torch.cat((pixels, torch.ones_like(pixels[:, :1])), dim=-1))
img_idxs.append(idxs[img2])
img_offs.append(offsets[img2])
cur_n.append(cur_n[-1] + len(pixels))
...
img_anchors[idx1] = (torch.cat(img_uv1), torch.cat(img_idxs), torch.cat(img_offs))
例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
// img_anchors[idx1] = (torch.cat(img_uv1), torch.cat(img_idxs), torch.cat(img_offs))
// 最终输出的anchor结构如下:
> img_anchors.keys()
dict_keys([0, 1, 2])
// img_uv1, 对应的像素坐标(已转换为齐次)
> img_anchors[0][0]
tensor([[ 0, 0, 1],
[164, 141, 1],
[164, 142, 1],
...,
[152, 382, 1],
[141, 388, 1],
[ 0, 511, 1]], device='cuda:0')
> img_anchors[0][0].shape
torch.Size([3337, 3])
// img_idxs, 对应的锚点序号
> img_anchors[0][1].shape
torch.Size([3337])
> img_anchors[0][1]
tensor([ 0, 632, 632, ..., 1711, 1745, 2268], device='cuda:0')
// img_offs, 相对于锚点的深度偏移
> img_anchors[0][2].shape
torch.Size([3337])
> img_anchors[0][2]
tensor([ -8140372.0000, 60670.4102, 282490.4062, ...,
38721220.0000, -5621286.5000, -34769248.0000], device='cuda:0')
corres, corres2d
1
2
3
4
for ...
tmp_pixels[img1, img2] = pixels.to(condense_dtype), match_confs.to(condense_dtype), slice(*cur_n[-2:])
# 拼接img1的所有图像的: (像素点, 锚点索引, 锚点深度偏移), 使用tmp_pixels存储分界
img_anchors[idx1] = (torch.cat(img_uv1), torch.cat(img_idxs), torch.cat(img_offs))
在之前能看到, img_anchors是将一张图像对应多张图像的img_uv1, img_idxs, img_offs使用torch.cat合并之后得到的。而拆分开所需要的cur_n被保存到了另一个tmp_pixels中,这一个变量之后经过了许多处理,分别进入到了corres2d和corres中。
corres是一个list, 存储了三个不同类型的值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
> len(corres)
3
# corres[0]
> type(corres[0])
<class 'torch.Tensor'>
> corres[0]
tensor([0., 0., 0., ..., 0., 0., 0.], device='cuda:0')
# corres[1]
> type(corres[1])
<class 'float'>
> corres[1]
14464.94921875
# corres[2]
> type(corres[2])
<class 'list'>
> len(corres[2])
6
> corres[2]
[ImgPair(img1=1, slice1=slice(0, 2089, None), pix1=tensor([[ 0., 0.],
[141....ce='cuda:0'), confs_sum=3586.342041015625), ImgPair(img1=0, slice1=slice(0, 2089, None), pix1=tensor([[ 0., 0.],
[164....ce='cuda:0'), confs_sum=3586.342041015625), ImgPair(img1=2, slice1=slice(0, 1248, None), pix1=tensor([[ 0., 0.],
[287....ce='cuda:0'), confs_sum=1230.834228515625), ImgPair(img1=0, slice1=slice(2089, 3337, None), pix1=tensor([[287., 0.],
[ ...ce='cuda:0'), confs_sum=1230.834228515625), ImgPair(img1=2, slice1=slice(1248, 3143, None), pix1=tensor([[ 0., 0.],
[2...ice='cuda:0'), confs_sum=2415.29833984375), ImgPair(img1=1, slice1=slice(2089, 3984, None), pix1=tensor([[287., 0.],
[ ...ice='cuda:0'), confs_sum=2415.29833984375)]
ImgPair类的属性如下:
1
2
3
4
5
6
7
8
9
10
11
12
<class '__main__.ImgPair'>
anchor_idxs1 =tuplegetter(3, 'Alias for field number 3')
anchor_idxs2 =tuplegetter(7, 'Alias for field number 7')
confs =tuplegetter(8, 'Alias for field number 8')
confs_sum =tuplegetter(9, 'Alias for field number 9')
img1 =tuplegetter(0, 'Alias for field number 0')
img2 =tuplegetter(4, 'Alias for field number 4')
pix1 =tuplegetter(2, 'Alias for field number 2')
pix2 = _tuplegetter(6, 'Alias for field number 6')
slice1 = _tuplegetter(1, 'Alias for field number 1')
slice2 = _tuplegetter(5, 'Alias for field number 5')
溯源一下可以发现, 最存储复杂的ImgPair对象的list的来自imgs_slices, ImgPair对象是由PairOfSlices创建的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
tmp_pixels = {}
for idx1, img1 in enumerate(img_path_list):
for img2, (pixels, match_confs) in pixels_confs.items():
...
cur_n.append(cur_n[-1] + len(pixels))
tmp_pixels[img1, img2] = pixels.to(condense_dtype), match_confs.to(condense_dtype), slice(*cur_n[-2:])
for img1, img2 in tmp_paths: # tmp_paths和
try:
# 提取一对相反的匹配结果
pix1, confs1, slice1 = tmp_pixels[img1, img2]
pix2, confs2, slice2 = tmp_pixels[img2, img1]
except KeyError:
continue
img1 = img_path_list.index(img1) # 获取图像的索引
img2 = img_path_list.index(img2)
confs = (confs1 * confs2).sqrt() # 两个图像对应像素的置信度相乘, 再开方
# prepare for loss_3d
all_confs.append(confs)
anchor_idxs1 = canonical_views[img_path_list[img1]][5][img_path_list[img2]] # 获取img1在img2的锚点的索引
anchor_idxs2 = canonical_views[img_path_list[img2]][5][img_path_list[img1]]
imgs_slices.append(PairOfSlices(img1, slice1, pix1, anchor_idxs1,
img2, slice2, pix2, anchor_idxs2,
confs, float(confs.sum())))
...
all_confs = torch.cat(all_confs)
corres = (all_confs, float(all_confs.sum()), imgs_slices)
而PairOfSlices定义如下:
1
2
3
from collections import namedtuple
PairOfSlices = namedtuple(
'ImgPair', 'img1, slice1, pix1, anchor_idxs1, img2, slice2, pix2, anchor_idxs2, confs, confs_sum')
namedtuple创建类似于class的不可变对象, 重点在于其轻量+不可变性质。使用时就是按顺序为其赋值。
1
2
3
PairOfSlices(img1, slice1, pix1, anchor_idxs1,
img2, slice2, pix2, anchor_idxs2,
confs, float(confs.sum())
因此
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
> img1
1
> img2
0
> slice1
slice(0, 2089, None)
> slice2
slice(0, 2089, None)
> pix1
tensor([[ 0., 0.],
[141., 133.],
[141., 133.],
...,
[122., 389.],
[127., 389.],
[287., 511.]], device='cuda:0')
> pix1.shape
torch.Size([2089, 2])
> pix2
tensor([[ 0., 0.],
[164., 141.],
[164., 142.],
...,
[141., 393.],
[142., 389.],
[287., 511.]], device='cuda:0')
> pix2.shape
torch.Size([2089, 2])
> anchor_idxs1
tensor([ 0, 593, 593, ..., 1743, 1743, 2303], device='cuda:0')
> anchor_idxs1.shape
torch.Size([2089])
> anchor_idxs2
tensor([ 0, 632, 632, ..., 1781, 1745, 2303], device='cuda:0')
> anchor_idxs2.shape
torch.Size([2089])
> confs
tensor([0., 0., 0., ..., 0., 0., 0.], device='cuda:0')
> float(confs.sum())
3586.342041015625
canonical_view
1
2
# prepare_canonical_data
canonical_views[img] = (pp, (H, W), focal.view(1), core_depth, pixels, idxs, offsets)
1
pp, shape, focal, anchors, pixels_confs, idxs, offsets = canonical_views[img1]
canon和canon2的生成还是要来剖析canonical_view函数
canonical_view输入的置信度最小值$1+e^x$计算得到的, 不会小于为1, 因此, 在手动调整网络输出的C时, 要置为1+1e-8而非0
1
2
3
4
# canonical pointmap is just a weighted average
confs11 = confs11.unsqueeze(-1) - 0.999
# canon是所有视角下的加权平均点云
canon = (confs11 * ptmaps11).sum(0) / confs11.sum(0)
对应的公式,使用置信度为权重对ptmap(也就是4个视角的点云)进行加权平均。
[ \text{canon}(x, y) = \frac{\sum_{i=1}^B \text{conf}{i}(x, y) \cdot \text{ptmap}{i}(x, y)}{\sum_{i=1}^B \text{conf}_{i}(x, y)} ]
canon_depth就是简单地取点云中每个点的z值(因为ptmaps11就是4组在相机1坐标系下点云, z值等于深度图的值)。使用subsample将canon_depth这一深度图进行切片操作。
1
canon_depth = ptmaps11[..., 2].unsqueeze(1)
S的作用是切片并提取中心点的深度值, 从subsample//2开始是为了让采样的点更加接近每个分块的中心点。创建切片对象S, 从subsample//2开始, 第二个参数stop=None表示不停止, 每隔subsample采样一次
假设canon_depth的shape为[B, 1, H, W], 那么得到的center_depth的shape就是[B, 1, H//subsample, W//subsample] 相当于提取了每个采样点最中间的深度值(是最中间吗)
1
2
S = slice(subsample // 2, None, subsample)
center_depth = canon_depth[:, :, S, S]
关于slice可以做一个简单的测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
>>> a = torch.arange(100).view(1,10,10)
>>> a
tensor([[[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
[20, 21, 22, 23, 24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35, 36, 37, 38, 39],
[40, 41, 42, 43, 44, 45, 46, 47, 48, 49],
[50, 51, 52, 53, 54, 55, 56, 57, 58, 59],
[60, 61, 62, 63, 64, 65, 66, 67, 68, 69],
[70, 71, 72, 73, 74, 75, 76, 77, 78, 79],
[80, 81, 82, 83, 84, 85, 86, 87, 88, 89],
[90, 91, 92, 93, 94, 95, 96, 97, 98, 99]]])
>>> c = a[:, b, b]
>>> c
tensor([[[11, 14, 17],
[41, 44, 47],
[71, 74, 77]]])
>>> a
tensor([[[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
[20, 21, 22, 23, 24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35, 36, 37, 38, 39],
[40, 41, 42, 43, 44, 45, 46, 47, 48, 49],
[50, 51, 52, 53, 54, 55, 56, 57, 58, 59],
[60, 61, 62, 63, 64, 65, 66, 67, 68, 69],
[70, 71, 72, 73, 74, 75, 76, 77, 78, 79],
[80, 81, 82, 83, 84, 85, 86, 87, 88, 89],
[90, 91, 92, 93, 94, 95, 96, 97, 98, 99]]])
>>> b
slice(1, None, 3)
>>> c
tensor([[[11, 14, 17],
[41, 44, 47],
[71, 74, 77]]])
>>> a
tensor([[[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
[20, 21, 22, 23, 24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35, 36, 37, 38, 39],
[40, 41, 42, 43, 44, 45, 46, 47, 48, 49],
[50, 51, 52, 53, 54, 55, 56, 57, 58, 59],
[60, 61, 62, 63, 64, 65, 66, 67, 68, 69],
[70, 71, 72, 73, 74, 75, 76, 77, 78, 79],
[80, 81, 82, 83, 84, 85, 86, 87, 88, 89],
[90, 91, 92, 93, 94, 95, 96, 97, 98, 99]]])
>>> b = slice(3//2, None, 3)
>>> b
slice(1, None, 3)
>>> c = a[:, b, b]
>>> c
tensor([[[11, 14, 17],
[41, 44, 47],
[71, 74, 77]]])
1
2
3
4
5
6
7
8
9
10
>>> b2 = slice(2//2, None, 2)
>>> b2
slice(1, None, 2)
>>> c2 = a[:, b2, b2]
>>> c2
tensor([[[11, 13, 15, 17, 19],
[31, 33, 35, 37, 39],
[51, 53, 55, 57, 59],
[71, 73, 75, 77, 79],
[91, 93, 95, 97, 99]]])
1
2
3
4
5
6
7
>>> b3 = slice(4//2, None, 4)
>>> b3
slice(2, None, 4)
>>> c3 = a[:, b3, b3]
>>> c3
tensor([[[22, 26],
[62, 66]]])
torch.clip(input, min, max) 用于限制张量中的元素值在指定范围内, 这里仅指定了下界min, 即数据类型的最小正数eps
1
2
3
# 例如
torch.float32,eps ≈ 1.1921e-07
torch.float64,eps ≈ 2.2204e-16
1
2
3
4
center_depth = torch.clip(center_depth, min=torch.finfo(center_depth.dtype).eps)
stacked_depth = F.pixel_unshuffle(canon_depth, subsample)
stacked_confs = F.pixel_unshuffle(confs11[:, None, :, :, 0], subsample)
F.pixel_unshuffle则是提取canon_depth和confs11的采样信息到stacked_depth和stacked_confs
1
2
3
4
5
6
7
8
> subsample
8
> canon_depth.shape
torch.Size([4, 1, 512, 288])
> stacked_depth.shape
torch.Size([4, 64, 64, 36])
> stacked_confs.shape
torch.Size([4, 64, 64, 36])
Q: stacked_xy.view(B, 2, -1, H, W)和xy[:, :, None, S, S]分别是下采样和slice得到的, 是否会存在采样点和采样中心是同一个, 导致计算得到的radius是0?
pixel_shuffle示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
> a = torch.arange(16).view(1, 4, 4)
> a
tensor([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]]])
> a.shape
torch.Size([1, 4, 4])
> b = F.pixel_unshuffle(a, 2)
> b.shape
torch.Size([4, 2, 2])
> b
tensor([[[ 0, 2],
[ 8, 10]],
[[ 1, 3],
[ 9, 11]],
[[ 4, 6],
[12, 14]],
[[ 5, 7],
[13, 15]]])
slice
1
2
3
4
5
6
7
8
9
10
> s = slice(2 // 2, None, 2)
> s
slice(1, None, 2)
> a.shape
torch.Size([1, 4, 4])
> a[:, s, s]
tensor([[[ 5, 7],
[13, 15]]])
> a[:, s, s].shape
torch.Size([1, 2, 2])
可以看到, 确确实实会出现这种, 采样点与采样中心是完全相同的情况。
仅分析默认的avg-angle模式
获取三维空间的xy坐标并同样使用F.pixel_unshuffle提取为stacked的状态
1
2
xy = ptmaps11[..., 0:2].permute(0, 3, 1, 2)
stacked_xy = F.pixel_unshuffle(xy, subsample)
有个可能混淆的地方: xy和stacked_xy并非是像素平面的xy坐标, 而是点云的xyz坐标的前2维
1
2
3
4
5
6
> ptmaps11.shape
torch.Size([4, 512, 288, 3])
> ptmaps11[..., 0:2].shape
torch.Size([4, 512, 288, 2])
> ptmaps11[..., 0:2].permute(0, 3, 1, 2).shape
torch.Size([4, 2, 512, 288])
1
2
3
B, _, H, W = stacked_xy.shape
stacked_radius = (stacked_xy.view(B, 2, -1, H, W) - xy[:, :, None, S, S]).norm(dim=1)
stacked_radius.clip_(min=1e-8)
stacked_xy.view(B, 2, -1, H, W)代表每个采样中的所有的采样点的xy坐标(前面用了F.pixel_unshuffle将维度与第1维也就是2混合了起来, 在这里又通过view(B, 2, -1, …)将混合的维度拆分开, 操作有点危险,如果涉及修改需要注意) xy[:, :, None, S, S]是采样中心的xy坐标
1
2
3
4
5
6
7
8
9
10
11
12
13
14
> xy.shape
torch.Size([4, 2, 512, 288])
> xy[:, :, None, S, S].shape
torch.Size([4, 2, 1, 64, 36])
> stacked_xy.shape
torch.Size([4, 128, 64, 36])
> stacked_xy.view(B, 2, -1, H, W).shape
torch.Size([4, 2, 64, 64, 36])
stacked_xy.view(B, 2, -1, H, W) - xy[:, :, None, S, S] # 广播
> (stacked_xy.view(B, 2, -1, H, W) - xy[:, :, None, S, S]).shape
torch.Size([4, 2, 64, 64, 36])
stacked_radius计算采样点与采样中心点的距离差计算norm, 最小值为1e-8
1
stacked_angle = torch.arctan((stacked_depth - center_depth) / stacked_radius)
采样点深度减去采样中心点深度,除以图像上的距离
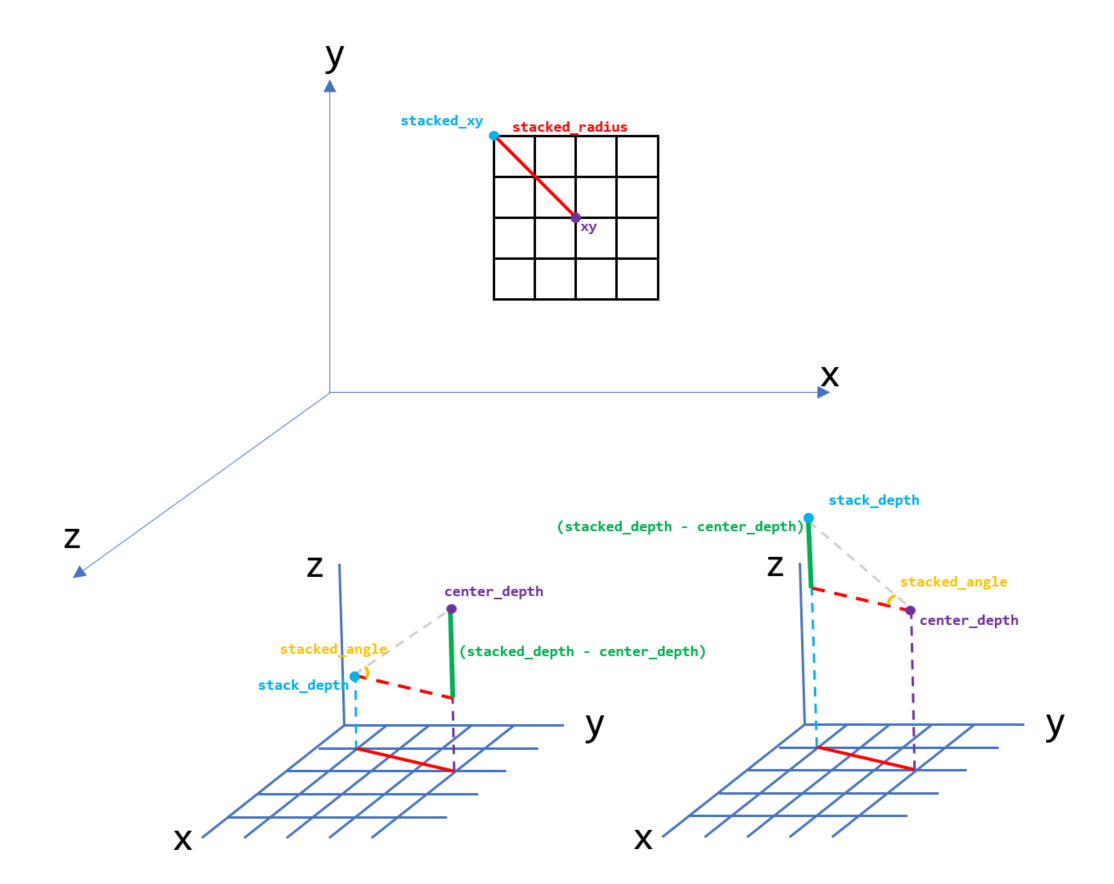
计算角度, 注意xy和stacked_xy并非是像素平面的xy坐标, 而是点云的xyz坐标的前2维, 这里是为了作图而简化, 不同batch下的stacked_radius可能是不同的
使用与前面同样的置信度加权方法, 对每个像素计算得到的角度stacked_angle进行加权, 得到每个采样区域的平均角度。然后使用该角度与采样点到采样中心的距离恢复平均深度。
举例?
这样其实和相机位姿有关、和投影到相机的深度有关。
1
2
3
4
5
6
7
# stacked_confs : torch.Size([4, 64, 64, 36])
# stacked_angle : torch.Size([4, 64, 64, 36])
avg_angle = (stacked_confs * stacked_angle).sum(dim=0) / stacked_confs.sum(dim=0)
# avg_angle : torch.Size([64, 64, 36])
stacked_depth = stacked_radius.mean(dim=0) * torch.tan(avg_angle)
# stacked_depth : torch.Size([64, 64, 36])
注意avg_angle是在第0维上进行平均, 是对所有参与匹配的对进行平均, 所以, 最后每个采样像素对应的角度的置信度加权操作是在所有匹配对上进行加权的。
如图中所示, 因为每个采样点到采样点中心的距离是始终固定的,
Q:这种方式与直接对不同batch的深度进行加权平均有什么不同?加了一个arctan和tan有什么不同?
A:可能的原因
1.防止近点/远点深度绝对值大的点的影响。如果使用采样点深度减去中心点深度值得到深度值差,然后直接进行平均。在有的视角下的对应像素点的深度值差异可能很大。
思考: 为什么添加mask会影响结果
因为深度的估计工作是在所有batch上进行平均的,
顺便说一下$B$的来源, 在prepare_canonical_data函数中, 所有的两两图像对会加载其匹配缓存, 函数load_corres会返回一个score, 如果该score为None, 那么该图像对的点云$X$和置信度$C$不会被保存和参与后续的处理。
检查load_corres函数:
1
2
3
4
5
6
7
def load_corres(path_corres, device, min_conf_thr):
print("load corres from {}".format(path_corres))
score, (xy1, xy2, confs) = torch.load(path_corres, map_location=device, weights_only=True)
valid = confs > min_conf_thr if min_conf_thr else slice(None)
# valid = (xy1 > 0).all(dim=1) & (xy2 > 0).all(dim=1) & (xy1 < 512).all(dim=1) & (xy2 < 512).all(dim=1)
# print(f'keeping {valid.sum()} / {len(valid)} correspondences')
return score, (xy1[valid], xy2[valid], confs[valid])
score对应的就是forward_mast3r中的matching_score
恢复分辨率, 首先除以采样中心的深度, 归一化?加1是为了防止深度值为0或负。
1
canon2 = F.pixel_shuffle((1 + stacked_depth / canon[S, S, 2]).unsqueeze(0), subsample).squeeze()
之所以有+1的操作, 可能是默认stacked_depth / canon[S, S, 2]能够进行归一化, 即计算后的结果不论正负, 绝对值一定是小于1的。但是事实并非如此, 而且即便是canon这一原始输入, 也只是保证值大于0.
测试, 对比无mask的静态场景图像, 观察canon2和stacked_depth
1
2
3
4
5
6
7
8
9
10
11
12
> (1+d0).max(), (1+d0).mean(), (1+d0).min()
(tensor(1.2649, device='cuda:0'), tensor(0.9425, device='cuda:0'), tensor(-0.0399, device='cuda:0'))
> (1+d1).max(), (1+d1).mean(), (1+d1).min()
(tensor(1.2799, device='cuda:0'), tensor(0.9536, device='cuda:0'), tensor(-0.0399, device='cuda:0'))
> (1+d2).max(), (1+d2).mean(), (1+d2).min()
(tensor(1.2939, device='cuda:0'), tensor(0.9629, device='cuda:0'), tensor(-0.0399, device='cuda:0'))
stacked_radius.max(), stacked_radius.mean(), stacked_radius.min()
(tensor(0.2712, device='cuda:0'), tensor(0.0025, device='cuda:0'), tensor(1.0000e-08, device='cuda:0'))
torch.tan(avg_angle).max(), torch.tan(avg_angle).mean(), torch.tan(avg_angle).min()
(tensor(105.4958, device='cuda:0'), tensor(-9.5625, device='cuda:0'), tensor(-116.5321, device='cuda:0'))
静态场景输入下:
1
2
3
4
5
6
> (1+d0).max(), (1+d0).mean(), (1+d0).min()
(tensor(1.0972, device='cuda:0'), tensor(0.9996, device='cuda:0'), tensor(0.9578, device='cuda:0'))
> (1+d1).max(), (1+d1).mean(), (1+d1).min()
(tensor(1.0945, device='cuda:0'), tensor(1.0003, device='cuda:0'), tensor(0.9665, device='cuda:0'))
> (1+d2).max(), (1+d2).mean(), (1+d2).min()
(tensor(1.0909, device='cuda:0'), tensor(1.0015, device='cuda:0'), tensor(0.9784, device='cuda:0'))
1
2
> canon_depth.max(), canon_depth.mean(), canon_depth.min()
(tensor(6.5513, device='cuda:0'), tensor(1.2415, device='cuda:0'), tensor(0.6252, device='cuda:0'))
1
2
3
4
5
6
7
8
9
10
11
> a = stacked_depth - center_depth
> a.max(), a.mean(), a.min()
(tensor(2.0889, device='cuda:0'), tensor(-1.2377, device='cuda:0'), tensor(-8.5773, device='cuda:0'))
> avg_angle.max(), avg_angle.mean(), avg_angle.min()
(tensor(1.5575, device='cuda:0'), tensor(0.0375, device='cuda:0'), tensor(-1.5541, device='cuda:0'))
> torch.tan(avg_angle).max(), torch.tan(avg_angle).mean(), torch.tan(avg_angle).min()
(tensor(75.2752, device='cuda:0'), tensor(0.0661, device='cuda:0'), tensor(-59.9621, device='cuda:0'))
> stacked_radius.max(), stacked_radius.mean(), stacked_radius.min()
(tensor(2.9509, device='cuda:0'), tensor(0.0150, device='cuda:0'), tensor(1.0000e-08, device='cuda:0'))
对比可以发现, 没有
感觉
如果要修改, 针对物体, 那么一个要修改的地方是在物体数据集上进行训练。另一个就是在这里恢复深度时。 大量的背景像素点无法计算平均置信度(或者说, 假如有4对数据, 但是仅有一个数据在当前的采样点上conf是>0的/是前景点, 那么计算得到的平均深度就是不可信的)
解决方案, 在对应的点上估计对应的深度, 但实际上, 对应的关系也是估计得到的。 因此必须想办法优化这里。
暂时先考虑简单的情况。(物体在转盘上, 在画面中心旋转, mask大小一致, 为物体的一部分(不包含背景点/包含很少的背景点))
深度恢复错误的原因
最直接的原因: stacked_depth的值太小了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
> idx = torch.where(canon[S, S, 2] > canon[S, S, 2][0, 0])
> a = (1 + stacked_depth / canon[S, S, 2])
> a.shape
torch.Size([64, 64, 36])
> a[idx[0], idx[1]]
tensor([[-inf, -inf, -inf, ..., -inf, -inf, -inf],
[-inf, -inf, -inf, ..., -inf, -inf, -inf],
[-inf, -inf, -inf, ..., -inf, -inf, -inf],
...,
[-inf, -inf, -inf, ..., -inf, -inf, -inf],
[-inf, -inf, -inf, ..., -inf, -inf, -inf],
[-inf, -inf, -inf, ..., -inf, -inf, -inf]], device='cuda:0')
> stacked_depth[idx[0], idx[1]]
tensor([[-1.1921e-07, -1.1921e-07, -1.1921e-07, ..., -1.1921e-07,
-1.1921e-07, -1.1921e-07],
[-1.1921e-07, -1.1921e-07, -1.1921e-07, ..., -1.1921e-07,
-1.1921e-07, -1.1921e-07],
[-1.1921e-07, -1.1921e-07, -1.1921e-07, ..., -1.1921e-07,
-1.1921e-07, -1.1921e-07],
...,
[-1.1921e-07, -1.1921e-07, -1.1921e-07, ..., -1.1921e-07,
-1.1921e-07, -1.1921e-07],
[-1.1921e-07, -1.1921e-07, -1.1921e-07, ..., -1.1921e-07,
-1.1921e-07, -1.1921e-07],
[-1.1921e-07, -1.1921e-07, -1.1921e-07, ..., -1.1921e-07,
-1.1921e-07, -1.1921e-07]], device='cuda:0')
> canon[idx[0], idx[1]]
tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
...,
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]], device='cuda:0')
所以问题在于
1
2
3
4
> stacked_radius.mean(dim=0)[idx[0], idx[1]].max(), stacked_radius.mean(dim=0)[idx[0], idx[1]].mean(), stacked_radius.mean(dim=0)[idx[0], idx[1]].min()
(tensor(0.1824, device='cuda:0'), tensor(0.0019, device='cuda:0'), tensor(1.0000e-08, device='cuda:0'))
> torch.tan(avg_angle)[idx[0], idx[1]].max(), torch.tan(avg_angle)[idx[0], idx[1]].mean(), torch.tan(avg_angle)[idx[0], idx[1]].min()
(tensor(18.2727, device='cuda:0'), tensor(-9.7231, device='cuda:0'), tensor(-21.6038, device='cuda:0'))
应该问题出在stacked_radius上, 也就是说, 点云中采样点的xy到采样中心的xy太近了。导致被clip_函数设置为了最小值1e-8
可能是我将forward中, 背景点置为[0,0,0]导致的?
测试不将点云X置为0
1
2
3
idx = torch.where(canon[S, S, 2] > canon[S, S, 2][0, 0])
stacked_radius.mean(dim=0)[idx[0], idx[1]].max(), stacked_radius.mean(dim=0)[idx[0], idx[1]].mean(), stacked_radius.mean(dim=0)[idx[0], idx[1]].min()
(tensor(0.2545, device='cuda:0'), tensor(0.0246, device='cuda:0'), tensor(1.0000e-08, device='cuda:0'))
1
2
stacked_radius = (stacked_xy.view(B, 2, -1, H, W) - xy[:, :, None, S, S]).norm(dim=1)
stacked_radius.clip_(min=1e-8)
尽管函数canonical_view输入的ptmaps11(点云)的z值都是大于0的, 但是无法保证计算相对深度的中间步骤中(stacked_depth - center_depth)计算得到的值是正的。因此arctan计算得到的角度可能是负的。只要角度是负的, 计算得到的stacked_depth就一定是负的。但是stacked_depth仅是相对深度, 为什么canon2会输出inf和-inf?问题出在恢复分辨率的步骤中。
1
stacked_angle = torch.arctan((stacked_depth - center_depth) / stacked_radius)
1
2
3
4
5
6
> canon_depth.shape
torch.Size([4, 1, 512, 288])
> canon_depth.max()
tensor(2.3613, device='cuda:0')
> canon_depth.min()
tensor(0., device='cuda:0')
观察下面的输出可以大概了解数据的情况, 首先使用idx过滤了那些深度为0或者很小的点, 这些点在作为分母被stacked_depth除以后必定会变为inf和-inf.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
> canon_depth.max()
tensor(2.3613, device='cuda:0')
> canon_depth.min()
tensor(0., device='cuda:0')
> canon[S, S, 2][0,0]
tensor(0., device='cuda:0')
> idx = torch.where(canon[S, S, 2] > canon[S, S, 2][0, 0])
> canon[S, S, 2][idx].max()
tensor(2.2480, device='cuda:0')
> canon[S, S, 2][idx].min()
tensor(1.6097, device='cuda:0')
> stacked_depth[0][idx[0], idx[1]].max()
tensor(0.4265, device='cuda:0')
> stacked_depth[0][idx[0], idx[1]].min()
tensor(-2.0451, device='cuda:0')
> stacked_depth[2][idx[0], idx[1]].max()
tensor(0.4732, device='cuda:0')
> stacked_depth[2][idx[0], idx[1]].min()
tensor(-1.9866, device='cuda:0')
> stacked_depth[1][idx[0], idx[1]].max()
tensor(0.4506, device='cuda:0')
> stacked_depth[1][idx[0], idx[1]].min()
tensor(-1.9866, device='cuda:0')
可以看到, 经过arctan和tan以及batch平均后, 重新恢复的相对深度stacked_depth并不能恢复到和canon相同的分布上, 而是整体往负轴的方向偏移。
1
2
3
d0 = stacked_depth[0][idx[0], idx[1]]/canon[S, S, 2][idx[0], idx[1]]
d1 = stacked_depth[1][idx[0], idx[1]]/canon[S, S, 2][idx[0], idx[1]]
d2 = stacked_depth[2][idx[0], idx[1]]/canon[S, S, 2][idx[0], idx[1]]
可以发现
1
2
3
4
5
6
7
8
9
10
11
12
> d0.max()
tensor(0.2649, device='cuda:0')
> d0.min()
tensor(-1.0399, device='cuda:0')
> d1.max()
tensor(0.2799, device='cuda:0')
> d1.min()
tensor(-1.0399, device='cuda:0')
> d2.max()
tensor(0.2939, device='cuda:0')
> d2.min()
tensor(-1.0399, device='cuda:0')
1
2
3
4
5
6
> (1+d0).max(), (1+d0).mean(), (1+d0).min()
(tensor(1.2649, device='cuda:0'), tensor(0.9425, device='cuda:0'), tensor(-0.0399, device='cuda:0'))
> (1+d1).max(), (1+d1).mean(), (1+d1).min()
(tensor(1.2799, device='cuda:0'), tensor(0.9536, device='cuda:0'), tensor(-0.0399, device='cuda:0'))
> (1+d2).max(), (1+d2).mean(), (1+d2).min()
(tensor(1.2939, device='cuda:0'), tensor(0.9629, device='cuda:0'), tensor(-0.0399, device='cuda:0'))
导出glb报错
报错原因: mask去除的背景没有从pts3d中排除, 因为检查pts3d中各个点云的点数量与缩放后图像的像素点数量是完全一样的, 因此那些背景点计算出的三维点坐标是nan, 导致计算错误。
1
2
3
4
5
6
7
8
9
10
11
12
13
> len(pts3d)
3
> type(pts3d[0])
<class 'numpy.ndarray'>
> pts3d[0].shape
(147456, 3)
> pts3d[1].shape
(147456, 3)
> pts3d[2].shape
(147456, 3)
> 512*288=147456
但是_convert_scene_output_to_glb其实是有mask的处理的
问题出在get_dense_pts3d函数中, 因为得到的pts3d深度全都是nan(即便mask标记为前景的点)
loss问题
在loss_3d函数中, 将点和点的计算结果最终都是会经过以下的处理
1
2
loss = confs @ pix_loss(pts3d_1, pts3d_2)
cf_sum = confs.sum()
因此, 只需要将loss3d_slices中, 背景的confs置为0即可解决loss_3d计算loss错误的问题。loss3d_slices来自imgs_slices
1
2
3
4
5
6
7
8
9
# Define which pairs are fine to use with matching
def matching_check(x): return x.max() > matching_conf_thr
is_matching_ok = {}
for s in imgs_slices:
is_matching_ok[s.img1, s.img2] = matching_check(s.confs)
# Prepare slices and corres for losses
dust3r_slices = [s for s in imgs_slices if not is_matching_ok[s.img1, s.img2]]
loss3d_slices = [s for s in imgs_slices if is_matching_ok[s.img1, s.img2]]
而
1
_, confs_sum, imgs_slices = corres
1
2
3
4
5
6
7
8
9
10
11
12
13
for idx1, img1 in enumerate(img_path_list):
for img2, (pixels, match_confs) in pixels_confs.items():
tmp_pixels[img1, img2] = pixels.to(condense_dtype), match_confs.to(condense_dtype), slice(*cur_n[-2:])
...
for img1, img2 in tmp_paths:
try:
# 提取一对相反的匹配结果
pix1, confs1, slice1 = tmp_pixels[img1, img2]
pix2, confs2, slice2 = tmp_pixels[img2, img1]
...
confs = (confs1 * confs2).sqrt()
追根溯源,pixels来自prepare_canonical_data中的pixels
1
2
3
4
5
6
7
8
9
10
11
12
13
14
if img == img1:
...
score, (xy1, xy2, confs) = load_corres(path_corres, device, min_conf_thr)
pixels[img2] = xy1, confs
...
if img == img2:
...
score, (xy1, xy2, confs) = load_corres(path_corres, device, min_conf_thr)
pixels[img1] = xy2, confs
...
canonical_views[img] = (pp, (H, W), focal.view(1), core_depth, pixels, idxs, offsets)
1
2
3
4
5
6
7
corres = extract_correspondences(descs, qonfs, device=device, subsample=subsample)
conf_score = (C11.mean() * C12.mean() * C21.mean() * C22.mean()).sqrt().sqrt()
matching_score = (float(conf_score), float(corres[2].sum()), len(corres[2]))
if cache_path is not None:
torch.save((matching_score, corres), mkdir_for(path_corres))
1
2
3
4
5
# 使用
score, (xy1, xy2, confs) = (matching_score, corres)
# score : matching_score
# (xy1, xy2, confs) : corres,
而corres来自
1
corres = extract_correspondences(descs, qonfs, device=device, subsample=subsample)
更有意思的是corres的shape为torch.Size([2089]), 与前面C11,C12,C21,C22的shape torch.Size([512, 288])完全不同。所以关键就在于函数extract_correspondences
1
2
3
4
5
6
7
8
9
10
11
12
corres[1].shape
torch.Size([2089, 2])
corres[2].shape
torch.Size([2089])
corres[0].shape
torch.Size([2089, 2])
torch.where(corres[2]!=0)[0].shape
torch.Size([1779])
qonfs[0].shape
torch.Size([512, 288])
qonfs[1].shape
torch.Size([512, 288])
估计焦距
estimate_focal_knowing_depth, 根据已知的深度信息和3D点来估计相机的焦距。
其输入包括:
1
2
3
4
5
6
7
8
9
10
11
12
pts3d:一个包含3D点的张量,形状为 (B, H, W, 3)
pp:相机的主点(principal point),通常是图像中心,形状为 (2,),包含 cx 和 cy 的值(图像的光心坐标)。 代码中由(H/2, W/2)计算得到。
focal_mode:指定焦距估计的方式,取值可以是 'median' 或 'weiszfeld',控制焦距计算的不同方法。
'median' 方法使用直接的中位数估计。
'weiszfeld' 方法使用加权最小二乘法来估计焦距。
min_focal:
max_focal: 设置焦距的最小值和最大值,用于对最终估计的焦距进行限制。
weiszfeld模式
最小化能量函数以获得收敛后的焦距focal:
\[E(\text{focal}) = \sum_i \left| \text{pixel}_i - \text{focal} \cdot \frac{(x_i, y_i)}{z_i} \right|\]很容易可以发现, focal的计算是所有像素都参与计算的, 因此前景背景点都融合在内其实是不对的。但是如果仅使用前景点, 估计得到的focal也未必是对的(因为这一类算法其实是依赖估计得到的绝对深度的正确与否, 因此到了这一步, 其实是假设了, 前面的多视角深度一致性约束已经满足了)。
Q1:能否将背景排除后, 单独使用前景估计深度? A: 在输入estimate_focal_knowing_depth前, 使用各张图像对应的mask对点云进行过滤。将背景点设置为Nan, 在估计focal时被排除掉。
Q2:这一步应该是针对每一个img单独估计了一个绝对深度canon和相对锚点深度canon2, 进而单独估计每个视角的焦距focal, 那么在整个for循环的过程中,这几次是相互独立的?至少在目前看来是独立的
Q3:如果像demo中一样勾选了shared intrinisc, 那么是估计完一个相机的内参后其他视角就跳过, 还是说多个视角的信息会联合估计一个内参?目前的canon, canon2, focal并没有看到联合优化的代码
目前看来, canon和canon2都没有直接传递到下一个函数中, 那么它们包含的信息去哪了?
canon直接采样变为了core_depth, 存储到了canonical_view中
canon2则是被输入到了anchor_depth_offsets函数中, 输出了idxs和offsets(idxs为各个像素点对应锚点的索引, offsets则是相对于对应锚点的深度偏移)
在condense_data函数中, 使用了一个img_anchors来保存所有图像的锚点索引与深度偏移。
来自canon的深度表示core_depth似乎没有做任何操作, 但是img_anchors在函数结尾有一定的处理:
1
2
3
4
5
6
7
# Subsample preds_21
subsamp_preds_21 = {}
for imk, imv in preds_21.items():
subsamp_preds_21[imk] = {}
for im2k, (pred, conf) in preds_21[imk].items():
idxs = img_anchors[imgs.index(im2k)][1]
subsamp_preds_21[imk][im2k] = (pred[idxs], conf[idxs]) # anchors subsample
preds_21 存储从当前幅图像(img)到 图像对 中另一幅图像的 子采样的 3D 点云预测值和对应的置信度
这段代码很有意思, 他遍历了preds_21的数据。preds_21是来自prepare_canonical_data的最后一个返回值。还是得回到该函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
preds_21 = {}
for img in tqdm(imgs):
...
for (img1, img2), ((path1, path2), path_corres, (mask1, mask2)) in tqdm(tmp_pairs.items()):
if img == img1:
X, C, X2, C2 = torch.load(path1, map_location=device, weights_only=True)
...
if img not in preds_21:
preds_21[img] = {}
# Subsample preds_21
preds_21[img][img2] = X2[::subsample, ::subsample].reshape(-1, 3), C2[::subsample, ::subsample].ravel()
if img == img2:
X, C, X2, C2 = torch.load(path2, map_location=device, weights_only=True)
...
if img not in preds_21:
preds_21[img] = {}
preds_21[img][img1] = X2[::subsample, ::subsample].reshape(-1, 3), C2[::subsample, ::subsample].ravel()
在图像2的点云的pointmap $X2$和置信度$C2$上, 按采样步长subsample下采样得到的。采样后的点云shape为(N, 3), 置信度shape为(N)
注意, 根据当前图像img在图像对中的位置不同(img1或img2), 读取的点云和置信度是不同的。
1
2
3
4
5
path1 = cache_path + f'/forward/{idx1}/{idx2}.pth'
path2 = cache_path + f'/forward/{idx2}/{idx1}.pth'
...
torch.save(to_cpu((X11, C11, X21, C21)), mkdir_for(path1))
torch.save(to_cpu((X22, C22, X12, C12)), mkdir_for(path2))
根据生成path1和path2保存的代码可以发现, “i/j.pth”对应的是在i坐标系下, i和j的点云与置信度。所以不论当前图像img在图像对中是img1还是img2, 加载的都是当前img为首的配置文件, 因此得到的点云X2都是在当前图像img坐标系下的另一幅图像的点云。preds_21是一个嵌套字典
1
2
3
4
5
6
7
8
9
10
preds_21
|---img1
|---img2
X_subsampled img2的点云在img1下的采样 (N, 3)
C_subsampled 对应的X_subsampled的置信度 (N)
|---img3
|---...
|---img2
...
...
回到condense_data函数, 使用preds_21.items()将嵌套字典的结构拆开。读取im2k图像的锚点在imk图像的对应点xy坐标与置信度,存储在subsamp_preds_21[imk][im2k]中。
1
2
3
4
5
6
7
# Subsample preds_21
subsamp_preds_21 = {}
for imk, imv in preds_21.items():
subsamp_preds_21[imk] = {}
for im2k, (pred, conf) in preds_21[imk].items():
idxs = img_anchors[imgs.index(im2k)][1]
subsamp_preds_21[imk][im2k] = (pred[idxs], conf[idxs]) # anchors subsample
重点在内部的for循环上, 为每个图像在subsamp_preds_21创建一个对应key-value对
1
subsamp_preds_21[imk] = {}
然后遍历该图像对应的图像, img_anchors同样来自condense_data, 注意提取的是im2k在imgs中的序号, 也就是说: img_anchors[imgs.index(im2k)][1] 提取的是preds_21第二层的字典key对应的img_idxs. 而img_anchors的第二个存储的是对应的锚点索引。
1
2
3
4
5
preds_21
|---img1
|---img2
X_subsampled img2的点云在img1下的采样 (N, 3)
C_subsampled 对应的X_subsampled的置信度 (N)
1
2
3
img_anchors[idx1] = (torch.cat(img_uv1), torch.cat(img_idxs), torch.cat(img_offs))
...
idxs = img_anchors[imgs.index(im2k)][1]
而马上又使用该锚点索引, 去获得im2k图像的锚点在imk上对应的的pred和conf.
1
subsamp_preds_21[imk][im2k] = (pred[idxs], conf[idxs])
需要注意, 返回的subsamp_preds_21直接将preds_21替代了。
1
2
3
4
5
6
7
8
def condense_data(imgs, tmp_paths, canonical_views, preds_21, dtype=torch.float32):
...
return imsizes, principal_points, focals, core_depth, img_anchors, corres, corres2d, subsamp_preds_21
...
imsizes, pps, base_focals, core_depth, anchors, corres, corres2d, preds_21 = \
condense_data(imgs, tmp_pairs, canonical_views, preds_21, dtype)
要想继续寻找, 就只能深入到sparse_scene_optimizer函数中了, 在该函数中, 好像只有loss_dust3r使用了preds_21.
sparse_scene_optimizer
看一下初始化部分:
外参
为每个相机创建初始化[0, 0, 0, 1]向量作为四元数旋转的初始值, 创建[0, 0, 0]作为位移的初始值。注意quats和trans都是nn.Parameter的类型, 即优化的目标参数。
1
2
3
vec0001 = torch.tensor((0, 0, 0, 1), dtype=dtype, device=device)
quats = [nn.Parameter(vec0001.clone()) for _ in range(len(imgs))]
trans = [nn.Parameter(torch.zeros(3, device=device, dtype=dtype)) for _ in range(len(imgs))]
pass
为每个相机创建全1向量, 以及media_depth(每个图像有一个“深度中值”, 暂时还不知道它有什么用)
然后就进入for循环, 针对每一个相机开始单独初始化, 首先是当前图像img在整个图像list中的下标序号。
1
idx = imgs.index(img)
为每张图像在init字典中创建一个空的子字典。
1
init_values = init.setdefault(img, {})
关于字典的setdefault(key, value)函数, 尝试将字典中设置key-value对, 如果不存在, 这创建该对并返回。如果已经存在,返回已有的value.
1
2
3
4
5
6
7
8
9
10
11
>>> a = {}
>>> a.setdefault(1,{})
{}
>>> a
{1: {}}
>>> a.setdefault(1,2)
{}
>>> a
{1: {}}
>>> a.setdefault(2,4)
4
尝试读取内参矩阵K
尝试从init中提取内参K, 如果init是空字典, 返回的K必然是None. 所以init字典的作用其实是为了从已有的配置中初始化。比如内参K已知的情况。
1
K = init_values.get('intrinsics')
如果init提供了内参矩阵:
\[\textit{focal} = mean(f_x, f_y)\] \[\textit{pp} = (cx, cy)\]结果存储到base_focals和pps中。
1
2
3
4
5
6
if K is not None:
K = K.detach()
focal = K[:2, :2].diag().mean()
pp = K[:2, 2]
base_focals[idx] = focal
pps[idx] = pp
举例:
1
2
3
4
5
6
7
8
9
10
11
12
>>> K = torch.arange(9).view(3, 3).float()
>>> K
tensor([[0., 1., 2.],
[3., 4., 5.],
[6., 7., 8.]])
>>> K[:2, :2].diag().mean()
tensor(2.)
>>> K[:2, :2].diag()
tensor([0., 4.])
>>> K[:2, 2]
tensor([2., 5.])
如果没有提供初始化的内参矩阵, pp会默认设置为[0.5, 0.5]. (函数参数输入的pp就是图像宽高除以2得到的)
1
pps[idx] /= imsizes[idx]
尝试读取深度图depth
1
2
3
4
5
6
depth = init_values.get('depthmap')
if depth is not None:
core_depth[idx] = depth.detach()
median_depths[idx] = med_depth = core_depth[idx].median()
core_depth[idx] /= med_depth
如果有提供, 存储到core_depth中, 相当于替换掉了参数的输入core_depth.
而如果没有, 则直接使用core_depth并计算, 得到之前提到的深度中值
即取当前图像深度的core_depth[idx]的中位数, 将所有的深度值除以该中位数。
1
2
median_depths[idx] = med_depth = core_depth[idx].median()
core_depth[idx] /= med_depth
sparse_scene_optimizer的输入参数core_depth直接来自:
1
core_depth = canon[subsample // 2::subsample, subsample // 2::subsample, 2]
没错, canon点云的z轴subsample步长的下采样。
1
2
core_depth[0].shape
torch.Size([64, 36])
发现了之前的bug, 之前的仅使用前景像素估计得到的focal并没有被用来估计深度图canon, 修改了之后, 背景点的canon值为Nan, 经过canon+subsample得到的core_depth 就会有Nan的部分, 要进行两处修改:
- 将Nan的部分排除掉, 然后计算median_depth
- 之后还有地方使用了深度
init尝试读取现有位姿
尝试加载init中的cam2w来获取”相机坐标系到世界坐标系的变换”。 将旋转转换为四元数,
计算了一个cam_center + rot @ trans_offset是为了什么?
值得注意的是: 这个偏移量是通过:
- 深度中值 med_depth
- 图像尺寸 imsizes[idx]
- 焦距 base_focals[idx]
- 图像主点pps[idx] 共同计算得到的
1
trans_offset = med_depth * torch.cat((imsizes[idx] / base_focals[idx] * (0.5 - pps[idx]), ones[:1, 0]))
0.5-pps[idx] 是像素坐标系(u, v)和主点的漂移。而且是百分比, 因为pps[idx]在默认状态下是(0.5,0.5) 这里应该是为了确保该相机的主点在其他位置的情况。
即: 如果主点不在画面的中心, 那么从像素坐标(u, v)计算得到的世界坐标系(X, Y, Z)与实际值就会差一个偏移量。
其对应的公式为:
\[\text{trans\_offset} = \text{med\_depth} \cdot \begin{bmatrix} \frac{\text{imsizes}[0]}{\text{base\_focals}} \cdot (0.5 - \text{pps}[0]) \\ \frac{\text{imsizes}[1]}{\text{base\_focals}} \cdot (0.5 - \text{pps}[1]) \\ 1 \end{bmatrix}\] \[\begin{bmatrix} u \\ v \\ 1 \\ \end{bmatrix} =K\begin{bmatrix} X \\ Y \\ Z \\ \end{bmatrix} =\begin{bmatrix} f_x & 0 & c_x \\ 0 & f_y & c_y \\ 0 & 0 & 1 \\ \end{bmatrix}\begin{bmatrix} X \\ Y \\ Z \\ \end{bmatrix} =\begin{bmatrix} f_x X + c_x \\ f_y Y + c_y \\ Z \\ \end{bmatrix} =Z \begin{bmatrix} \frac{f_xX + c_x}{Z} \\ \frac{f_yY + c_y}{Z} \\ 1 \\ \end{bmatrix}\]将这个公式逆过来
\[\begin{bmatrix} u Z \\ v Z \\ Z \end{bmatrix} =\begin{bmatrix} f_x X + c_x \\ f_y Y + c_y \\ 1 \end{bmatrix}\] \[\begin{bmatrix} u Z - c_x \\ v Z - c_y \\ Z \end{bmatrix} =\begin{bmatrix} f_x X \\ f_y Y \\ 1 \end{bmatrix}\] \[\begin{bmatrix} \frac{u Z - c_x}{f_x} \\ \frac{v Z - c_y}{f_y} \\ Z \end{bmatrix} =\begin{bmatrix} X \\ Y \\ 1 \end{bmatrix}\]最早pp是通过
1
pp = torch.tensor([W / 2, H / 2], device=device)
计算得到的, 而在sparse_scene_optimizer函数中稍前的部分中(内参部分), 通过除以图像的尺寸, 因此默认的pps[idx]值是(0.5, 0.5).
1
pps[idx] /= imsizes[idx] # default principal_point would be (0.5, 0.5)
而在这里, 使用0.5减去, 是为了弥补归一化? 因此默认情况下, trans_offset只有z轴是不为0的. 即
\[\text{trans\_offset} = \begin{bmatrix} 0 \\ 0 \\ \text{med\_depth} \end{bmatrix}\]1
2
3
4
5
6
7
8
9
cam2w = init_values.get('cam2w')
if cam2w is not None:
rot = cam2w[:3, :3].detach() # Rotation matrix
cam_center = cam2w[:3, 3].detach() # (x, y, z)
quats[idx].data[:] = roma.rotmat_to_unitquat(rot)
trans_offset = med_depth * torch.cat((imsizes[idx] / base_focals[idx] * (0.5 - pps[idx]), ones[:1, 0]))
trans[idx].data[:] = cam_center + rot @ trans_offset
del rot
assert False, 'inverse kinematic chain not yet implemented'
不过既然没有提供init_values, 所以这一段代码暂时不会触发。
shared_intrinsics
shared_intrinsics有什么用?
当shared_intrinsics为True时, 将所有的视角的相机内参(焦距focal和主点pp)作为一个共享的参数进行优化。为False时每个相机有独立的内参参数进行优化。
1
2
3
4
5
6
7
8
9
if shared_intrinsics:
# Optimize a single set of intrinsics for all cameras. Use averages as init.
confs = torch.stack([torch.load(pth, weights_only=True)[0][2].mean() for pth in canonical_paths]).to(pps)
weighting = confs / confs.sum()
pp = nn.Parameter((weighting @ pps).to(dtype))
pps = [pp for _ in range(len(imgs))]
focal_m = weighting @ base_focals
log_focal = nn.Parameter(focal_m.view(1).log().to(dtype))
log_focals = [log_focal for _ in range(len(imgs))]
分析一下这段代码,
torch.load加载的缓存文件来自:
1
2
3
4
def prepare_canonical_data
...
if cache:
torch.save(to_cpu(((canon, canon2, cconf), focal)), mkdir_for(cache))
可以看到其只加载了cconf, 并归一化作为权重weighting, 对pps进行加权平均, 作为优化参数pp. 并且重置了pps, 将所有的pps都设置为了None.
对焦距进行了加权平均得到focal_m, 并将其对数形式作为优化参数log_focal. 而且整个log_focals中的值全是同一个focal_m. (之后会变得不同吗?)
反观shared_intrinsics为False的情况:
1
2
3
else:
pps = [nn.Parameter(pp.to(dtype)) for pp in pps]
log_focals = [nn.Parameter(f.view(1).log().to(dtype)) for f in base_focals]
是否共享内参只是影响了两个list: pps与log_focals的初始化
1
2
3
diags = imsizes.float().norm(dim=1)
min_focals = 0.25 * diags # diag = 1.2~1.4*max(W,H) => beta >= 1/(2*1.2*tan(fov/2)) ~= 0.26
max_focals = 10 * diags
计算图像对角线长度diags, 约束估计的焦距范围[1/4, 10]倍diags (所以如果是裁剪图像的情况, 需要注意这里!)
make_K_cam_depth
make_K_cam_depth函数就做了几件事情
- 根据log_focals和pps生成内参矩阵$K$, 是的这里不涉及优化, 单纯地就是生成矩阵格式的内参矩阵。
- 通过最小生成树(mst)计算每个相机的全局外参矩阵 cam2w
- 考虑主点偏移、全局缩放和深度信息,重新调整相机的平移参数。
- 根据深度模式生成归一化的深度图。
- 最终返回内参𝐾、外参 (inv(cam2w),cam2w)(inv(cam2w),cam2w) 和深度图 depthmaps
能够观察到不同, shared_intrinsics为True时, 初始焦距为K[0, 0, 0], 因为所有视角的焦距都是相同的初始化。 shared_intrinsics为False时, 初始焦距为K[:, 0, 0], n个视角有n个$K$矩阵。
1
2
3
4
if shared_intrinsics:
print('init focal (shared) = ', to_numpy(K[0, 0, 0]).round(2))
else:
print('init focals =', to_numpy(K[:, 0, 0]))
如果trans为None, 表示仅构造内参矩阵$K$并返回, 不做其他操作。
1
2
3
4
5
6
7
8
# make intrinsics
focals = torch.cat(log_focals).exp().clip(min=min_focals, max=max_focals)
pps = torch.stack(pps)
K = torch.eye(3, dtype=dtype, device=device)[None].expand(len(imgs), 3, 3).clone()
K[:, 0, 0] = K[:, 1, 1] = focals
K[:, 0:2, 2] = pps * imsizes
if trans is None:
return K
而make_K_cam_depth函数在整个稀疏场景优化中有3处调用, 分别是初始化、每一轮迭代中、迭代结束后。而且在迭代前后的调用中, 都是为了使用log_focals和pps获取内参矩阵$K$.
1
K = make_K_cam_depth(log_focals, pps, None, None, None, None)
函数的剩余部分先暂时不分析, 继续往下.
[更新]外参的计算
使用输入的参数quat和trans构建相机之间的相对姿态。相机i相对于相机j的
1
2
3
rel_cam2cam = torch.eye(4)[None].expand(len(imgs), 4, 4).clone()
rel_cam2cam[:, :3, :3] = roma.unitquat_to_rotmat(...)
rel_cam2cam[:, :3, 3] = trans
mst是一个最小生成树, mst[0]为根节点, 第一个相机/view. 从根节点开始, 计算所有相机的camera-to-world变换。
1
2
3
tmp_cam2w[mst[0]] = rel_cam2cam[mst[0]]
for i, j in mst[1]:
tmp_cam2w[j] = tmp_cam2w[i] @ rel_cam2cam[j]
low-rank
对深度图进行参数化和低秩投影(low-rank proj)
默认参数下, xp_depth=False, lora_depth=False
1
2
3
4
5
6
7
8
# spectral low-rank projection of depthmaps
if lora_depth:
core_depth, lora_depth_proj = spectral_projection_of_depthmaps(
imgs, K, core_depth, subsample, cache_path=cache_path, **lora_depth)
if exp_depth:
core_depth = [d.clip(min=1e-4).log() for d in core_depth]
core_depth = [nn.Parameter(d.ravel().to(dtype)) for d in core_depth]
log_sizes = [nn.Parameter(torch.zeros(1, dtype=dtype, device=device)) for _ in range(len(imgs))]
我们先分析最基础的情况, 即lora_depth和exp_depth均为False.
1
2
core_depth = [nn.Parameter(d.ravel().to(dtype)) for d in core_depth]
log_sizes = [nn.Parameter(torch.zeros(1, dtype=dtype, device=device)) for _ in range(len(imgs))]
- 将n张深度图d, 通过ravel展开成一维向量, 并使用nn.Parameter参数化.
- 将每张图像对应的size也作为一个单独的数值, 同样使用使用nn.Parameter进行参数化。
在优化过程中, 优化的参数是每个视角的深度图core_depth和尺度log_sizes(对数形式).
slice
1
2
3
4
5
6
7
8
# Fetch img slices
_, confs_sum, imgs_slices = corres
# Define which pairs are fine to use with matching
def matching_check(x): return x.max() > matching_conf_thr
is_matching_ok = {}
for s in imgs_slices:
is_matching_ok[s.img1, s.img2] = matching_check(s.confs)
corres来源:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
all_confs = []
imgs_slices = []
corres2d = {img: [] for img in range(len(imgs))}
# tmp_paths记录特定图像对(img1, img2)的匹配像素点, 匹配置信度, 以及在总的中的起止cur_n[-2:]
for img1, img2 in tmp_paths:
try:
# 提取一对相反的匹配结果
pix1, confs1, slice1 = tmp_pixels[img1, img2]
pix2, confs2, slice2 = tmp_pixels[img2, img1]
except KeyError:
continue
img1 = imgs.index(img1) # 获取图像的索引
img2 = imgs.index(img2)
confs = (confs1 * confs2).sqrt() # 两个图像对应像素的置信度相乘, 再开方
# prepare for loss_3d
all_confs.append(confs)
anchor_idxs1 = canonical_views[imgs[img1]][5][imgs[img2]] # 获取img1在img2的锚点的索引
anchor_idxs2 = canonical_views[imgs[img2]][5][imgs[img1]]
imgs_slices.append(PairOfSlices(img1, slice1, pix1, anchor_idxs1,
img2, slice2, pix2, anchor_idxs2,
confs, float(confs.sum())))
all_confs = torch.cat(all_confs)
corres = (all_confs, float(all_confs.sum()), imgs_slices)
其中confs_sum在后续没有使用, 仅使用了imgs_slices
1
_, confs_sum, imgs_slices = corres
继续:
1
2
3
4
5
# Define which pairs are fine to use with matching
def matching_check(x): return x.max() > matching_conf_thr
is_matching_ok = {}
for s in imgs_slices:
is_matching_ok[s.img1, s.img2] = matching_check(s.confs)
数据示例
1
2
3
4
5
6
7
8
9
10
11
12
> s.confs
tensor([0., 0., 0., ..., 0., 0., 0.], device='cuda:0')
> s.confs.shape
torch.Size([2089])
> s.confs.max()
tensor(5.5267, device='cuda:0')
> s.img1
1
> s.img2
0
> is_matching_ok
{(1, 0): tensor(True, device='cuda:0'), (0, 1): tensor(True, device='cuda:0'), (2, 0): tensor(False, device='cuda:0'), (0, 2): tensor(False, device='cuda:0'), (2, 1): tensor(False, device='cuda:0'), (1, 2): tensor(False, device='cuda:0')}
所以, 在当前的测试例子中, 仅有图像对(0, 1)和(1, 0)是通过了check的, 如果将阈值降低, 得到的结果会变好吗?
A: 将matching阈值降低, 将更多的对添加到匹配中去, 目前来看明显提升了结果的质量。但是其副作用是什么?过滤的作用、两个loss的slice分别对应什么?
获取每个PairOfSlices对象的confs属性, 通过matching_check检查是否超过阈值matching_conf_thr. 将check的结果保存到is_matching_ok中.
注意, matching_check中的阈值matching_conf_thr默认是5.0, 这也是根据经验确定的.
经过matching_check的对(slice)会进入loss3d_slices, 否则是dust3r_slices.
1
2
3
# Prepare slices and corres for losses
dust3r_slices = [s for s in imgs_slices if not is_matching_ok[s.img1, s.img2]]
loss3d_slices = [s for s in imgs_slices if is_matching_ok[s.img1, s.img2]]
corres2d的来源-condense_data
以下这段代码来自函数condense_data 主要作用是对 corres2d 中的图像间匹配点数据进行清洗,只保留匹配状态通过检查的图像对(根据 is_matching_ok 的结果).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
for idx1, img1 in enumerate(imgs):
corres2d = {img: [] for img in range(len(imgs))}
# tmp_paths记录特定图像对(img1, img2)的匹配像素点, 匹配置信度, 以及在总的中的起止cur_n[-2:]
for img1, img2 in tmp_paths:
try:
pix1, confs1, slice1 = tmp_pixels[img1, img2]
pix2, confs2, slice2 = tmp_pixels[img2, img1]
except KeyError:
continue
img1 = imgs.index(img1) # 获取图像的索引
img2 = imgs.index(img2)
confs = (confs1 * confs2).sqrt() # 两个图像对应像素的置信度相乘, 再开方
...
# prepare for loss_2d
corres2d[img1].append((pix1, confs, img2, slice2))
corres2d[img2].append((pix2, confs, img1, slice1))
corres2d = [aggreg_matches(img, m) for img, m in corres2d.items()]
tmp_pixels中存储的pix, confs, slice对应的shape如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
> tmp_pixels[('./data/hand/rgb/00060.png', './data/hand/rgb/00050.png')][0].shape
torch.Size([2089, 2])
> tmp_pixels[('./data/hand/rgb/00050.png', './data/hand/rgb/00060.png')][0].shape
torch.Size([2089, 2])
> tmp_pixels[('./data/hand/rgb/00060.png', './data/hand/rgb/00050.png')][1].shape
torch.Size([2089])
> tmp_pixels[('./data/hand/rgb/00050.png', './data/hand/rgb/00060.png')][1].shape
torch.Size([2089])
> tmp_pixels[('./data/hand/rgb/00050.png', './data/hand/rgb/00060.png')][2]
slice(0, 2089, None)
> tmp_pixels[('./data/hand/rgb/00060.png', './data/hand/rgb/00050.png')][2]
slice(0, 2089, None)
在sparse_scene_optimizer函数中使用corres2d中的内容.
1
for cci, (img1, pix1, confs, confsum, imgs_slices) in enumerate(corres2d):
corres2d中, 存储的是在另一个图像中的对应像素pix1, pix2, 以及双向的置信度乘积开方结果confs
aggreg_matches
1
2
3
4
5
def aggreg_matches(img1, list_matches):
pix1, confs, img2, slice2 = zip(*list_matches)
all_pix1 = torch.cat(pix1).to(condense_dtype)
all_confs = torch.cat(confs).to(condense_dtype)
return img1, all_pix1, all_confs, float(all_confs.sum()), [(j, sl2) for j, sl2 in zip(img2, slice2)]
输入了img1, list_matches, 第二个参数是corres2d中的values.
1
corres2d = [aggreg_matches(img, m) for img, m in corres2d.items()]
而
1
2
corres2d[img1].append((pix1, confs, img2, slice2))
corres2d[img2].append((pix2, confs, img1, slice1))
所以第二个参数对应的是结构形如:(pix1, confs, img2, slice2)的输入。
list_matches是aggreg_matches的第二个参数, 对应一个m, 也就是corres2d的一个key对应的value. corres2d[img1]对应的是一个list.
打印如下:
1
2
3
4
5
6
7
8
9
10
> len(list_matches)
4
> list_matches[0][0].shape
torch.Size([2089, 2])
> list_matches[0][1].shape
torch.Size([2089])
> list_matches[0][2]
1
> list_matches[0][3]
slice(0, 2089, None)
在aggreg_matches函数中将匹配点pix1和置信度confs通过torch.cat拼接为all_pix1和all_confs.
返回值:
- 此时的img1是图像在img_lists中的下标序号.
- all_pix1 对应的像素坐标的拼接
- all_confs
- 置信度求和
- img2, slice2组成的元组
cleaned_corres2d
对2d的对应关系进行清理. 该list存放的是五个元素的元组(img1, pix1_filtered, confs_filtered, cf_sum, cleaned_slices)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
cleaned_corres2d = []
for cci, (img1, pix1, confs, confsum, imgs_slices) in enumerate(corres2d):
cf_sum = 0
pix1_filtered = []
confs_filtered = []
curstep = 0
cleaned_slices = []
for img2, slice2 in imgs_slices:
if is_matching_ok[img1, img2]:
tslice = slice(curstep, curstep + slice2.stop - slice2.start, slice2.step)
pix1_filtered.append(pix1[tslice])
confs_filtered.append(confs[tslice])
cleaned_slices.append((img2, slice2))
curstep += slice2.stop - slice2.start
if pix1_filtered != []:
pix1_filtered = torch.cat(pix1_filtered)
confs_filtered = torch.cat(confs_filtered)
cf_sum = confs_filtered.sum()
cleaned_corres2d.append((img1, pix1_filtered, confs_filtered, cf_sum, cleaned_slices))
打印imgs_slices:
1
2
3
4
5
6
7
8
9
10
> len(imgs_slices)
4
> imgs_slices[0]
(1, slice(0, 2089, None))
> imgs_slices[1]
(1, slice(0, 2089, None))
> imgs_slices[2]
(2, slice(0, 1248, None))
> imgs_slices[3]
(2, slice(0, 1248, None))
slice中的三个值对应的是start, stop, step三个属性.
1
2
> pix1.shape
torch.Size([6674, 2])
到这里就很好理解了, 使用cur_step记录当前位置, 使用slice的start, stop, step来生成全局的起止位置tslice来切分pix1, confs这些使用torch.cat拼接的结构.
这段代码的作用是: 仅保留is_matching_ok为True的图像对的pix1, confs和(img2, slice2), 最终重新torch.cat拼接, 格式与corres2d完全相同。 结果保存在cleaned_corres2d中,
loss
可以看到, 函数中连续定义了4个函数: loss_dust3r, loss_3d, loss_2d, optimize_loop
如果定义了init中的freeze属性, trainable值为False, quats, trans, log_sizes的requires_grad_都会设置为False. 即所有的参数都不会训练, 反之, 默认情况下, 旋转quats, trans和log_sizes这三个都是可训练的。
在初期时, 相机内参和深度图都是不参与优化的。
coarse match
在粗匹配阶段, loss_3d作为loss_func传入到optimize_loop函数中, 初始配置如下:
1
2
3
4
loss_func: loss3d
lr1: 0.2
niter1: 500
loss1: gamma_loss(1.1)
loss3d值很小, 但是loss2d值却很大? 问题可能出在这里。
先测试不使用res_fine结果重建的场景, 检查是否正确。
loss3d
计算3D点的匹配误差
loss2d
计算2D重投影误差

loss值大也是合理的, 因为green视角下重投影误差确实很大。

在forward_mast3r中, 已经对属于背景的点的置信度C进行了处理, 但是对应的X并没有额外的处理。这可能是导致优化出错的问题?
2025.2.12更新
在处理SAM+RGB输入输出的点云和相机内外参时,对mast3r中loss2d有了一点新的认识:
首先, 其和loss3d处理的输入均不来自函数参数, loss2d的处理的输入来自:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
cleaned_corres2d = []
for cci, (img1, pix1, confs, confsum, imgs_slices) in enumerate(corres2d):
cf_sum = 0
pix1_filtered = []
confs_filtered = []
curstep = 0
cleaned_slices = []
for img2, slice2 in imgs_slices:
if is_matching_ok[img1, img2]:
tslice = slice(curstep, curstep + slice2.stop - slice2.start, slice2.step)
pix1_filtered.append(pix1[tslice])
confs_filtered.append(confs[tslice])
cleaned_slices.append((img2, slice2))
curstep += slice2.stop - slice2.start
if pix1_filtered != []:
pix1_filtered = torch.cat(pix1_filtered)
confs_filtered = torch.cat(confs_filtered)
cf_sum = confs_filtered.sum()
cleaned_corres2d.append((img1, pix1_filtered, confs_filtered, cf_sum, cleaned_slices))
其中的corres2d是之前处理过的, 代表两组图像间的点对关系。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
> len(corres2d)
3
> corres2d[0]
(0, tensor([[ 0., 0.],
[164., 141.],
[164., 142.],
...,
...],
[ 0., 511.]], device='cuda:0'), tensor([0., 0., 0., ..., 0., 0., 0.], device='cuda:0'), 9634.3525390625, [(...), (...), (...), (...)])
> img1
0
> imgs_slices
[(1, slice(0, 2089, None)), (1, slice(0, 2089, None)), (2, slice(0, 1248, None)), (2, slice(0, 1248, None))]
> pix1
tensor([[ 0., 0.],
[164., 141.],
[164., 142.],
...,
[152., 382.],
[141., 388.],
[ 0., 511.]], device='cuda:0')
> pix1.shape
torch.Size([6674, 2])
SparseGA
写了一个函数保存res_coarse和res_fine的结果: 内参, 外参, depthmap和点云
不论res_coarse还是res_fine都发现一个问题:
像大多数的网络估计结果一样, 视角和点云之间有很多离散的噪点, 而这些点似乎并不存在于最终的glb格式输出下

res_coarse和res_fine的保存步骤与最终glb输出之间, 就差了一步SparseGA, 所以SparseGA做了什么?
初始化
SparseGA的参数输入有res_fine or res_coarse
1
2
3
4
5
6
>>> a = [1, 2, 3]
>>> b = [4,5,6]
>>> a or b
[1, 2, 3]
>>> None or b
[4, 5, 6]
这意味着, 如果res_fine存在, 优先使用res_fine, 否则才会使用res_fine.
__init__函数没什么好说的, 主要是res_fine中的参数传递, 唯一需要注意的可能就是点云的颜色pts3d_color来自anchors建立与图像的映射. 即每个点云的颜色是其对应的锚点的颜色。
1
2
3
4
5
6
7
8
9
class SparseGA():
def __init__(self, img_paths, pairs_in, res_fine, anchors, canonical_paths=None):
...
for i in range(len(self.imgs)):
im = self.imgs[i]
x, y = anchors[i][0][..., :2].detach().cpu().numpy().T
self.pts3d_colors.append(im[y, x])
assert self.pts3d_colors[-1].shape == self.pts3d[i].shape
self.n_imgs = len(self.imgs)
####
初始化之后, SparseGA对象(被命名为scene)做了什么:
1
2
3
4
5
6
7
8
9
10
11
12
13
# get optimized values from scene
rgbimg = scene.imgs
focals = scene.get_focals().cpu()
cams2world = scene.get_im_poses().cpu()
...
scene_state = SparseGAState(scene, False, None, outdir)
...
outfile = get_3D_model_from_scene(not verbose_save, scene_state, min_conf_thr, as_pointcloud, mask_sky,
clean_depth, transparent_cams, cam_size, TSDF_thresh)
scene.imgs是获取初始化传入的img_paths读取的全部图像,
scene.get_focals则是创建了一个长度n的tensor存放n张图像对应的n个内参矩阵$K$的$f_x$
scene.get_im_poses则是直接获取res_fine或res_coarse中的cam2w(相机外参), 是一个(n, 4, 4)的torch.tensor代表n个相机的extrinsic matrix.
看来唯一的处理只可能发生在SparseGAState中
1
2
3
scene_state = SparseGAState(scene, False, None, outdir)
outfile = get_3D_model_from_scene(not verbose_save, scene_state, min_conf_thr, as_pointcloud, mask_sky, clean_depth, transparent_cams, cam_size, TSDF_thresh)
get_3D_model_from_scene
处理可能是在
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
def get_3D_model_from_scene(silent, scene_state, min_conf_thr=2, as_pointcloud=False, mask_sky=False,
clean_depth=False, transparent_cams=False, cam_size=0.05, TSDF_thresh=0):
"""
extract 3D_model (glb file) from a reconstructed scene
"""
if scene_state is None:
return None
outfile = scene_state.outfile_name
if outfile is None:
return None
# get optimized values from scene
scene = scene_state.sparse_ga
rgbimg = scene.imgs
focals = scene.get_focals().cpu()
cams2world = scene.get_im_poses().cpu()
# 3D pointcloud from depthmap, poses and intrinsics
if TSDF_thresh > 0:
tsdf = TSDFPostProcess(scene, TSDF_thresh=TSDF_thresh)
pts3d, _, confs = to_numpy(tsdf.get_dense_pts3d(clean_depth=clean_depth))
else:
pts3d, _, confs = to_numpy(scene.get_dense_pts3d(clean_depth=clean_depth))
msk = to_numpy([c > min_conf_thr for c in confs])
return _convert_scene_output_to_glb(outfile, rgbimg, pts3d, msk, focals, cams2world, as_pointcloud=as_pointcloud, transparent_cams=transparent_cams, cam_size=cam_size, silent=silent)
可能是
1
msk = to_numpy([True for c in confs])
测试将msk全部置为True
1
msk = to_numpy([c >= 0 for c in confs])


稠密化
get_dense_pts3d从canonical_paths读取缓存文件, 来获得稠密化的点云。不仅读取了密集点云, 还读取了每个点对应的置信度confs.
自然地会有疑问
Q:为什么要在最后进行稠密化? 为什么不一直对密集点云进行处理? 密集点云与稀疏点云之间有什么关系?
映射关系
最近在修改mask mast3r, 使其能够支持超过>2张的rgb+mask输入:
映射关系如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
输入:
3张图像路径
images
[
images[0]
img
Tensor, shape: torch.Size([1, 3, 512, 288])
true_shape
ndarray, shape: (1, 2)
idx
int (图像在原始输入路径list中的序号)
instance
str (图像的原始路径)
images[1]
images[2]
]
$C^2_3$能够得到6对图像, pairs的长度为6
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
pairs
[
pairs[0]
pairs[0][0]
img
Tensor, shape: torch.Size([1, 3, 512, 288])
true_shape
ndarray, shape: (1, 2)
idx
int
instance
str
pairs[0][1]
pairs[1]
pairs[2]
...
pairs[5]
]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
output
view1
img
Tensor, shape: torch.Size([6, 3, 512, 288])
true_shape
Tensor, shape: torch.Size([6, 2])
idx
list, length: 6
instance
list, length: 6
view2
img
Tensor, shape: torch.Size([6, 3, 512, 288])
true_shape
Tensor, shape: torch.Size([6, 2])
idx
list, length: 6
instance
list, length: 6
pred1
pts3d
Tensor, shape: torch.Size([6, 512, 288, 3])
conf
Tensor, shape: torch.Size([6, 512, 288])
desc
Tensor, shape: torch.Size([6, 512, 288, 24])
desc_conf
Tensor, shape: torch.Size([6, 512, 288])
pred2
conf
Tensor, shape: torch.Size([6, 512, 288])
desc
Tensor, shape: torch.Size([6, 512, 288, 24])
desc_conf
Tensor, shape: torch.Size([6, 512, 288])
pts3d_in_other_view
Tensor, shape: torch.Size([6, 512, 288, 3])
loss
NoneType
我之前认为使用view1对应pred1, pred1使用view1中对应的idx去寻找mask和image即可。但似乎有错误。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
view1
img
Tensor, shape: torch.Size([2, 3, 512, 288])
true_shape
Tensor, shape: torch.Size([2, 2])
idx
list, length: 2
instance
list, length: 2
view2
img
Tensor, shape: torch.Size([2, 3, 512, 288])
true_shape
Tensor, shape: torch.Size([2, 2])
idx
list, length: 2
instance
list, length: 2
pred1
pts3d
Tensor, shape: torch.Size([2, 512, 288, 3])
conf
Tensor, shape: torch.Size([2, 512, 288])
desc
Tensor, shape: torch.Size([2, 512, 288, 24])
desc_conf
Tensor, shape: torch.Size([2, 512, 288])
pred2
conf
Tensor, shape: torch.Size([2, 512, 288])
desc
Tensor, shape: torch.Size([2, 512, 288, 24])
desc_conf
Tensor, shape: torch.Size([2, 512, 288])
pts3d_in_other_view
Tensor, shape: torch.Size([2, 512, 288, 3])
loss
NoneType
其中
1
2
3
4
output['view1']['idx']
[1, 0]
output['view2']['idx']
[0, 1]
mask问题
观察inference输出的output中的pts3d和pts3d_in_other_view后发现, 作者之前在issue中回答说单纯地使用mask重置conf可能不会有效的原因了。

或者说它可以发挥作用,仅当mask分割出的物体是一个静态的物体,和背景的相对位置是不变的。此时背景参与回归和match其实并不会影响对物体的匹配和重建。但刚才的这个说法也并不严谨,经过测试, 如果对输入的图像进行裁剪, 提取特征后估计的相机内参也会受到影响, 因此在提取特征前尽量不要对图像进行裁剪
pts3d和conf是inference之后网络输出的结果, 估计相对位姿和重建使用同一坐标框架下的两个view的点云, 但是此时的背景信息其实已经发挥过作用了(Vit encoder提取patch信息)。在某种程度上, 匹配已经发生过了, 因此使用mask对conf进行置0操作(在指数中是置1)不会完全起作用,因为此时回归得到的pts3d已经包含了背景的信息, 即:pts3d的回归和之后的对齐操作其实已经被mask去除的信息影响过了

color+crop+whiteBG: 在inference之前, 将mask去除部分的像素统一设置为白色
顺带一提, 上图中, 反光问题其实也会严重影响匹配

前背景分离与patch embedding
我在测试过程中,尝试将背景的颜色设置为(0,0,0), 并通过将其conf设置为1.0的方式使其不参与匹配。
我们首先看看, 背景颜色设置为0, 对其估计得到的pointmap有什么影响。
输入白色背景后的匹配结果
然后,我们发现,在边缘处, 有一些点的回归坐标向前飞出, 非常接近相机。有意思的是,这些“飞点”的情况只发生在pts3d中, 在pts3d_in_other中并不存在。可能是测试的过少?
飞点图像
如果尝试拿这些点去初始化并训练3dgs, 最好进行一定的预处理,因为它们实际上并没有对齐。而且光照的影响是不可忽视的
焦距估计
desc_conf和conf
desc_conf, conf, pts3d 都来自于postprocess函数. 这一段来自于CroCo3DStereo的_downstream_head, 即decoder已经结束, 根据下游任务生成对应的head的阶段。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def postprocess(out, depth_mode, conf_mode, desc_dim=None, desc_mode='norm', two_confs=False, desc_conf_mode=None):
if desc_conf_mode is None:
desc_conf_mode = conf_mode
fmap = out.permute(0, 2, 3, 1) # B,H,W,D
res = dict(pts3d=reg_dense_depth(fmap[..., 0:3], mode=depth_mode))
if conf_mode is not None:
res['conf'] = reg_dense_conf(fmap[..., 3], mode=conf_mode)
if desc_dim is not None:
start = 3 + int(conf_mode is not None)
res['desc'] = reg_desc(fmap[..., start:start + desc_dim], mode=desc_mode)
if two_confs:
res['desc_conf'] = reg_dense_conf(fmap[..., start + desc_dim], mode=desc_conf_mode)
else:
res['desc_conf'] = res['conf'].clone()
return res
Q:desc_conf和conf有什么不同?
conf和desc_conf都来自函数reg_dense_conf, 但是其输入有所不同:
1
res['conf'] = reg_dense_conf(fmap[..., 3], mode=conf_mode)
1
2
3
4
if two_confs:
res['desc_conf'] = reg_dense_conf(fmap[..., start + desc_dim], mode=desc_conf_mode)
else:
res['desc_conf'] = res['conf'].clone()
我们运行一个测试的例子看一下计算的过程,首先看参数的输入:
1
2
3
4
5
6
7
out: [1, 29, 512, 288]
depth_mode: ('exp', -inf, inf)
conf_mode: ('exp', 1, inf)
desc_dim: 24
desc_mode: 'norm'
two_confs: True
desc_conf_mode: ('exp', 0, inf)
输入的out是dpt输出的pts3d,与local_features的拼接. fmap就是feature map, 是对out变换为(B, H, W, D)得到的。
1
2
3
4
5
6
7
8
self.head_local_features = Mlp(in_features=idim,
hidden_features=int(hidden_dim_factor * idim),
out_features=(self.local_feat_dim + self.two_confs) * self.patch_size**2)
local_features = self.head_local_features(cat_output) # B,S,D
local_features = local_features.transpose(-1, -2).view(B, -1, H // self.patch_size, W // self.patch_size)
local_features = F.pixel_shuffle(local_features, self.patch_size) # B,d,H,W
out = torch.cat([pts3d, local_features], dim=1)
Sparse GA
在mast3r的demo中, 有这么一段注释:
1
# Sparse GA (forward mast3r -> matching -> 3D optim -> 2D refinement -> triangulation)
可以发现整个sparse global alignment分为4个阶段:
1.
dust3r
优化
论文中的公式5
\[\chi^* = \arg\min_{\chi, P, \sigma} \sum_{e \in \mathcal{E}} \sum_{v \in e} \sum_{i=1}^{HW} C_i^{v,e} \left\| \chi_i^v - \sigma_e P_e X_i^{v,e} \right\|.\]https://github.com/naver/dust3r/blob/main/dust3r/cloud_opt/base_opt.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
class BasePCOptimizer (nn.Module):
...
def forward(self, ret_details=False):
pw_poses = self.get_pw_poses() # cam-to-world
pw_adapt = self.get_adaptors()
proj_pts3d = self.get_pts3d()
# pre-compute pixel weights
weight_i = {i_j: self.conf_trf(c) for i_j, c in self.conf_i.items()}
weight_j = {i_j: self.conf_trf(c) for i_j, c in self.conf_j.items()}
loss = 0
if ret_details:
details = -torch.ones((self.n_imgs, self.n_imgs))
for e, (i, j) in enumerate(self.edges):
i_j = edge_str(i, j)
# distance in image i and j
aligned_pred_i = geotrf(pw_poses[e], pw_adapt[e] * self.pred_i[i_j])
aligned_pred_j = geotrf(pw_poses[e], pw_adapt[e] * self.pred_j[i_j])
li = self.dist(proj_pts3d[i], aligned_pred_i, weight=weight_i[i_j]).mean()
lj = self.dist(proj_pts3d[j], aligned_pred_j, weight=weight_j[i_j]).mean()
loss = loss + li + lj
if ret_details:
details[i, j] = li + lj
loss /= self.n_edges # average over all pairs
if ret_details:
return loss, details
return loss
其中get_pw_poses获得的就是公式中的$\sigma_e P_e$, 搭配adapt用来将pointmap变换为全局对齐的pointmap并计算loss.
在BasePCOptimizer的初始化函数中,我们可以发现
1
2
self.POSE_DIM = 7
self.pw_poses = nn.Parameter(rand_pose((self.n_edges, 1+self.POSE_DIM))) # pairwise poses
其在POSE_DIM(4维度的四元数旋转+3维的位移)的基础上再+1,这一个额外的维度在后面的函数get_pw_scale中使用,它被用来优化尺度.
1
2
3
4
def get_pw_scale(self):
scale = self.pw_poses[:, -1].exp() # (n_edges,)
scale = scale * self.get_pw_norm_scale_factor()
return scale
1
2
3
4
5
6
7
8
9
10
11
12
def _get_poses(self, poses):
# normalize rotation
Q = poses[:, :4]
T = signed_expm1(poses[:, 4:7])
RT = roma.RigidUnitQuat(Q, T).normalize().to_homogeneous()
return RT
def get_pw_poses(self): # cam to world
RT = self._get_poses(self.pw_poses)
scaled_RT = RT.clone()
scaled_RT[:, :3] *= self.get_pw_scale().view(-1, 1, 1) # scale the rotation AND translation
return scaled_RT
| 其中signed_expm1对输入的(n, 3)的n个位移,先记录符号sign(负数返回-1, 0返回0, 正数返回1), 然后torch.expm1对绝对值计算$e^{ | x | }-1$ |
1
2
3
def signed_expm1(x):
sign = torch.sign(x)
return sign * torch.expm1(torch.abs(x))
综上, 完成了操作
\[sign(x)(e^{|x|}-1)\]主要是为了数值稳定性
然后使用四元数Q和位移T创建一个刚体变换矩阵RT(齐次形式, 4×4), 返回后与缩放因子相乘self.get_pw_scale().view(-1, 1, 1)
可以发现,forward函数主要是根据已经得到的pose计算loss, 优化的代码在别处
最小生成树
在官方的demo中使用的init方法是mst, 使用的是最小生成树, 迭代300轮。
1
2
3
4
5
6
7
8
9
10
11
12
def compute_global_alignment(self, init=None, niter_PnP=10, **kw):
if init is None:
pass
elif init == 'msp' or init == 'mst':
init_fun.init_minimum_spanning_tree(self, niter_PnP=niter_PnP)
elif init == 'known_poses':
init_fun.init_from_known_poses(self, min_conf_thr=self.min_conf_thr,
niter_PnP=niter_PnP)
else:
raise ValueError(f'bad value for {init=}')
return global_alignment_loop(self, **kw)
minimum_spanning_tree
来到init_im_pose.py, 这里我们能够发现minimum_spanning_tree
估计焦距f
在dust3r中, 输入一个(W,)
1
im_focals[i] = estimate_focal(pred_i[i_j])
有两种模式: median和最小二乘法估计焦距
\[f_x = \frac{u \cdot z}{x}, \quad f_y = \frac{v \cdot z}{y}\]mast3r
使用fast_reciprocal_NNs函数的地方主要有两个
1.visloc.py中的coarse_match和fine_match
2.sparse_ga.py中的extract_correspondences提取对应关系时
visloc
数据集准备
https://github.com/naver/mast3r/issues/20