论文阅读-A Construct-Optimize Approach to Sparse View Synthesis without Camera Pose
CF3DGS
自建数据集测试
desk image:1214 train time: 1:41:00
eval 266 frames avr_PSNR: 24.562
核心
与之前的colmap-free是同一赛道(你醒啦, COLMAP-Free 3D Gaussian Splatting已经变成CVPR2024了)
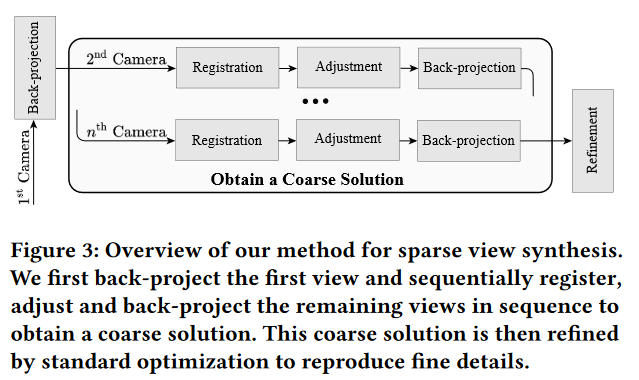
开发了一种无相机姿态的稀疏视图重建构建+优化方法, 使用单目深度并且将像素投影到3D空间中,在构建过程中,通过检测训练视图和对应的渲染图像之间的2D对应来进行优化。开发了一个统一的可微分pipeline用于相机注册和调整相机的位姿和深度,接着进行反投影。
引入了gs中 expected surface的概念, 对于优化至关重要。这一步粗略解决问题,然后通过标准优化能够实现低通滤波和refine。
Contribution
1.提出了一个统一可微分pipeline, 使用对应关系作为监督, 用于无相机位姿的稀疏视图合成(Sec.3.1, Sec.3.2)
2.提出了一个gs可微近似表面 用于对应监督(Sec.3.3)
method
作者希望给予密集先验(dense prior), 即估计得到的单目深度, 但是优化仍然很重要, 因此该方法称为construct-and-optimize
一个用于构建的简单方案是:估计相机姿态, 然后根据估计的深度, 将像素反投影到场景中
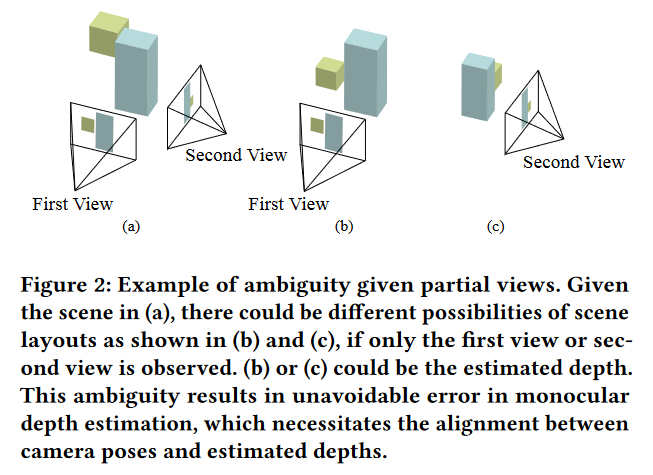
但是这样存在问题:首先,相机姿态和深度是紧密耦合的(看下图),其次,现有的单目深度估计算法都不包含相机姿态。最后,相机姿态估计算法基本都是不会使用和对齐单目深度。同一个场景在多个视图上的反向投影可能会不一致。
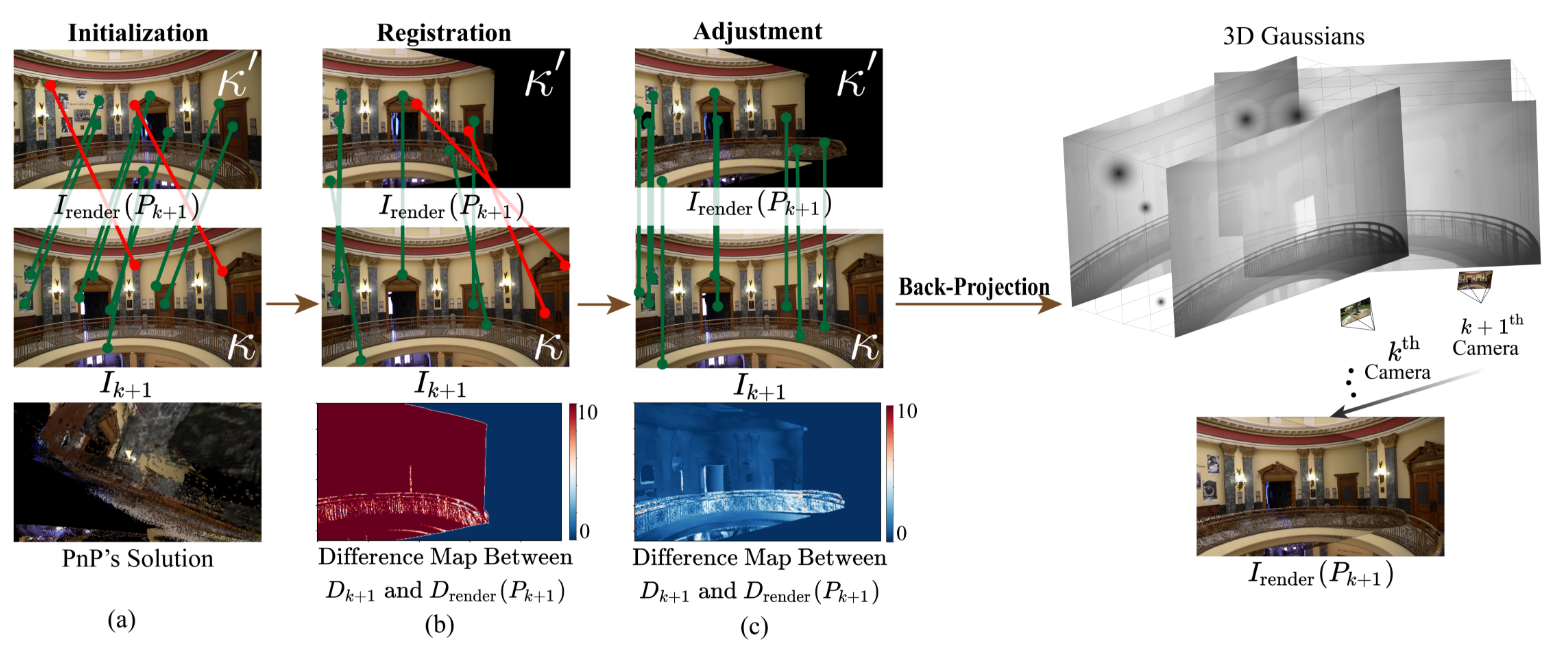
pipeline如下图所示, 逐步进行,不断构建场景,对于下一个新来的未注册的view, 首先在registration阶段估计其位姿, 然后调整之前的相机位姿并对其单目深度。这就是所谓的”adjustment”, 最后, 下一view的像素投影到世界坐标系, 作为3dgs, 因此不需要知道相机的位姿。