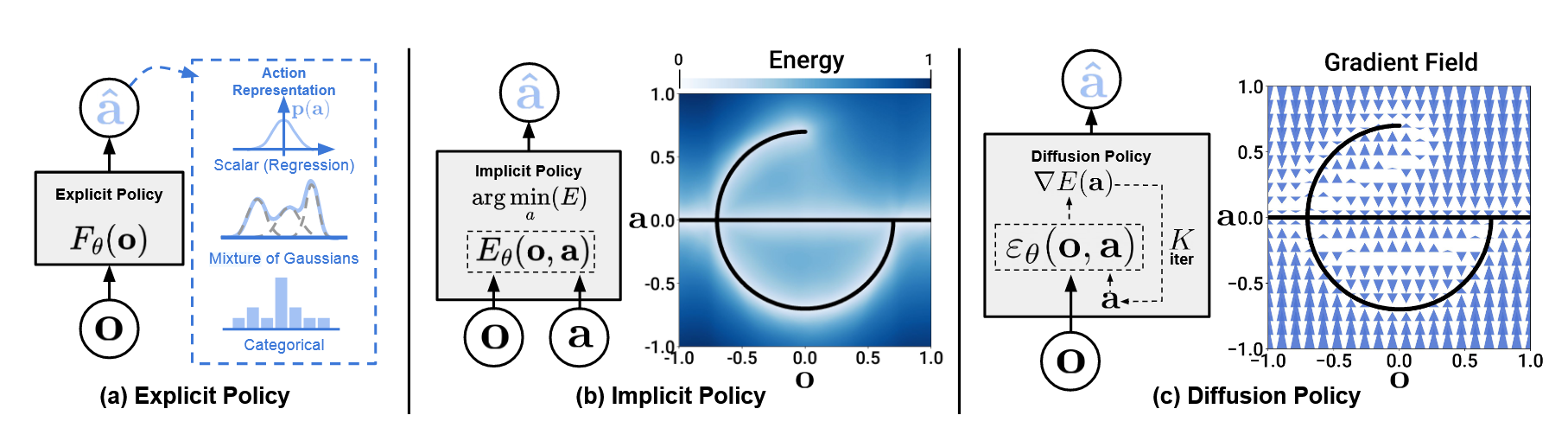
Diffusion Policy
representing a robot’s visuomotor policy as a conditional denoising process. Diffusion Policy learns the gradient of the action-distribution score function and iteratively optimizes with respec...
representing a robot’s visuomotor policy as a conditional denoising process. Diffusion Policy learns the gradient of the action-distribution score function and iteratively optimizes with respec...

https://www.kaggle.com/code/yosukeyama/rsna2025-32ch-img-infer-lb-0-69-share 举例: Found 176 DICOM files in series “176 个 DICOM” 通常表示同一个 Series 里有 176 个 instance,而一个 instance(SOPInstanceUID)通常就是一...
安装Google Cloud CLI(包含gsutil) 无法定位软件包 google-cloud-cli 确保有必要的依赖 sudo apt-get install -y apt-transport-https ca-certificates gnupg curl 删除旧的cloud.google的GPG key sudo rm -f /usr/share/keyrings/clo...

https://www.physicalintelligence.company/blog/pi0 Before start 梳理了一下VLA的发展历程,理论上应当从RT-1, RT-2, RT-X系列开始阅读,但是考虑到24和25年相关新工作的大量出现,尽快入门更加重要。目前的阅读思路是pi0, OpenVLA, RDT, pi0.5 About Generalist Robot P...
记录自己从0入门VLA(Vision-Language-Action) 只是记录而非教程 图标 说明 :white_check_mark: 基本完成 不排除有新增的可能 :black_square_button: 尚未完成 ...
pytorch3d CUB_HOME # which nvcc # /usr/local/cuda-11.8/bin/nvcc export CUB_HOME=/usr/local/cuda-11.8/include/cub You need C++17 to compile PyTorch https://github.com/facebookresearch/pytorch3d...
被动旋转(coordinate frame change) 交换坐标系,保持物理方向不变,重新定义xyz方向 被动旋转作用到作用在坐标系上,而不是作用在物体上,让坐标轴旋转,而不影响向量 主动旋转作用在向量上 \(v' = Rv\) 被动旋转作用在坐标系上,而不是物体上,坐标轴旋转R, 而物体保持不动。 不动的向量$v$在新的坐标系中的表达变成 \(v' = R^T v\) 为什么$...
最近想看的一些论文 来自:Andrea Vedaldi: “Feed-forward 4D: from scene to categories” paper about imgs DPM:(Dynamic Point Maps: A Versatile Representation for ...
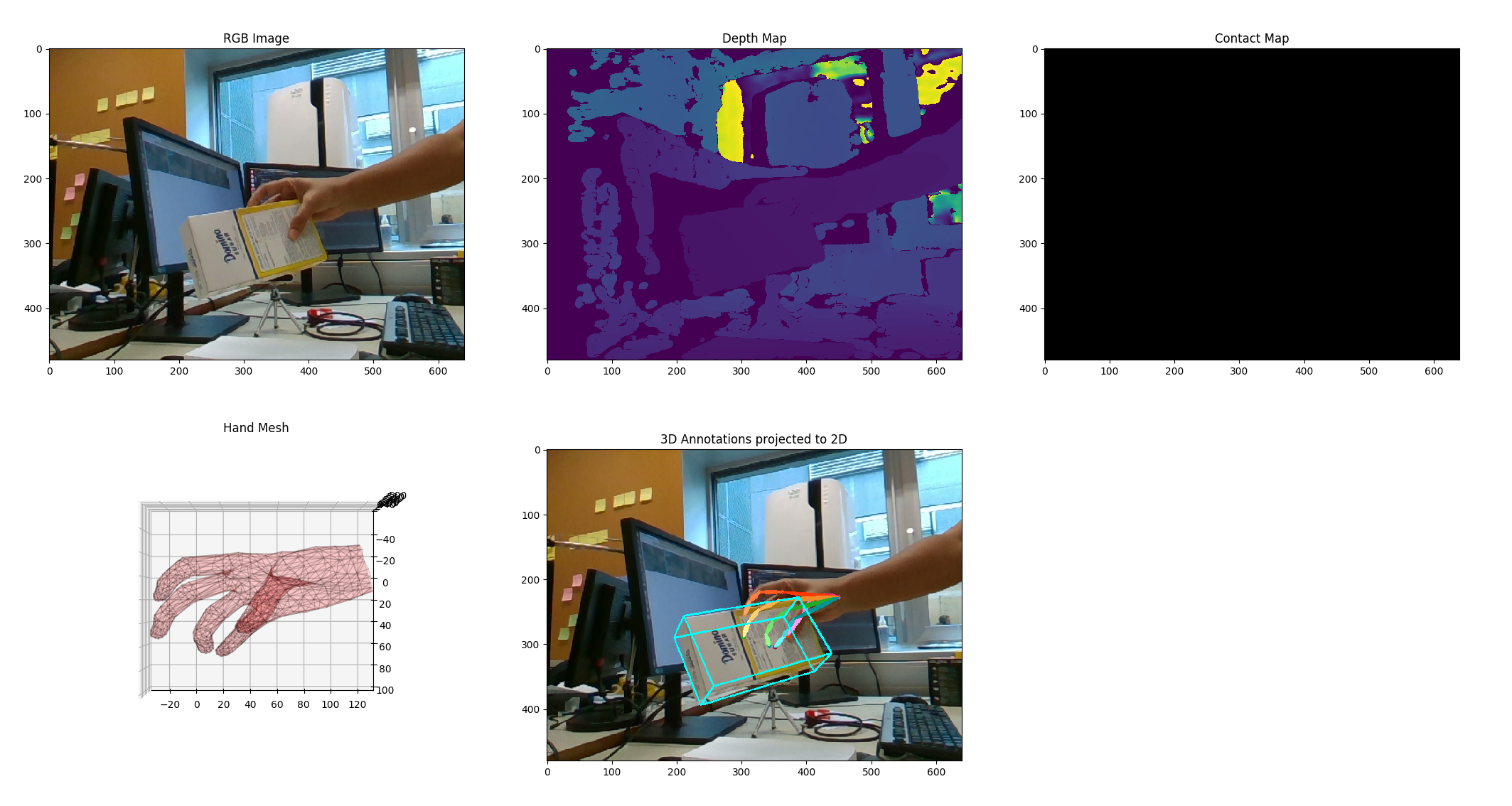
export MANO_PATH=/home/cxx/workspace/HO3R/ho3d/mano/mano_v1_2 export YCB_PATH=/home/cxx/workspace/HO3R/ho3d/ycb_models/models export DB_PATH=/home/cxx/dataset/HO3D_v3 python setup_mano.py ${MANO_...
joycon的传感器本身分辨率很低,没有磁力计,仅imu和加速度计,因此仅能依赖积分来获得对朝向的估计,而且随着时间推移会有累积误差,无法获得绝对朝向和位置。 关于joycon-R带的IR摄像头,我也不认为它能做太多的事情。将其固定在特定位置,(如纸壳钢琴中检测遮挡,我觉得这就是极限了) device https://betterjoy.net/connect-joy-cons-to-...