
kaggle-imc25 n-st Place Solution
像站在大门前倏忽了一瞬间 https://www.kaggle.com/competitions/image-matching-challenge-2025/discussion/583058 自己的知识储备和工程能力远远不够,导致无法驾驭现有的工具和方法。 作者承诺会公开代码,等待学习… 值得注意的点 Rotation correction MASt3R的特征提取, 不...
像站在大门前倏忽了一瞬间 https://www.kaggle.com/competitions/image-matching-challenge-2025/discussion/583058 自己的知识储备和工程能力远远不够,导致无法驾驭现有的工具和方法。 作者承诺会公开代码,等待学习… 值得注意的点 Rotation correction MASt3R的特征提取, 不...
Env win10 +RTX 3080, 使用CUDA 11.8 + TensorRT 8.5 GA + Python 3.10 CUDA >= 11.4 https://developer.nvidia.com/cuda-downloads >nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 20...
‘a’ tag is missing a reference 症状为build -> Test site过不了. 报错 ‘a’ tag is missing a reference 原因: 使用了 [GaussianObject: High-Quality 3D Object Reconstruction from Four Views with Gaussian Splatt...
goolge盘很多是带动态验证的,使用浏览器的复制下载链接是无法下载的(只能下载很小一段就会停止) 正常流程可参考:https://blog.csdn.net/diqiudq/article/details/126070602 遇到的问题 弹出的认证链接输入账号登录后显示 解决方案:去控制台添加测试用户 https://console.cloud.google.com 在配置...

Spann3R, SLAM3R, VGGT以及现在的MUSt3R 都对DUSt3R和MASt3R的pairwise输入结构进行了扩展。 why how Spann3R 🔁 第一次 Forward Pass(用于 Query memory) 目标:提取图像特征,读取 memory,并更新下一时刻的 query。 对应公式为: 图像编码: [f_t^I = \text{Enco...
DUSt3R, MASt3R等预训练模型名字中总是包含dpt, dpt是什么? DUSt3R_ViTLarge_BaseDecoder_512_dpt.pth ## head一般是网络的最后一层或几层,用于将backbone提取的特征转为特定任务的输出。 dust3r中,有两种head类型, 分别是pts3d和dpt。 Vision transformers for dense ...
离散数学回旋镖系列 :) 想到一个问题: 假设有n个数字,有一个函数能够每次取一个数(概率相同),取完之后对应的标签位置为1,(可能取到位置为1的数,如果取到,则重新取),取完$n$个不同的数字最终的时间复杂度是多少 优惠券收集问题 概念: 期望 = 事件 * 事件发生的概率 在优惠券收集问题中,设总共有$n$种不同的优惠券,每次收集时得到一种新的优惠券的概率取决于已经收集到的优惠券...
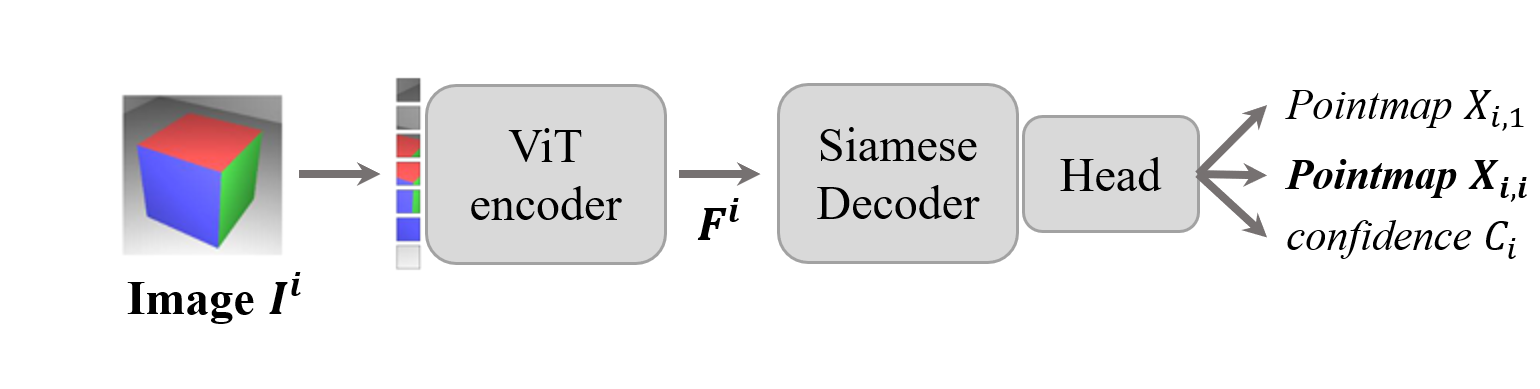
关于mast3r, dust3r, global alignment的一些理解 最近在kaggle上使用mast3r作为baseline, 遇到了一些disk溢出的问题 在sparse_global_alignment阶段, 会将所有的图像和图像对输入到forward_mast3r,计算对应关系,并将计算的结果缓存到cache目录下,之后的prepare_canonical_data阶段...
方法名称 核心策略 是否支持增量 效率表现 精度 & 全局一致性 发布时间 DUSt3R 两视图Transformer回归局部点云,需后续全局优化对齐 否 O(n²) 成对重建,效率低 精度高但误差累积,全局一致性依赖后处理优化 ...

第一次打kaggle比赛因为没什么经验,中间浪费了很多时间和提交次数来了解数据、测试流程和模型部署。 虽然没拿到牌子, 还是学到了不少东西。下次继续努力 :) 结束第一天总结 相比于自己搭建框架, 优先去复刻往年金牌的思路,注意其中提到的技巧以及baseline(其实写论文也是如此,站在巨人的肩膀上,不要因为非我发明综合征而去重复造轮子) 本地s...