# [论文阅读]Shape Prior Deformation for Categorical 6D Object Pose and Size Estimation
# 在前面
这篇按顺序应该是NOCS,CASS之后的工作,最大的贡献是提出了类先验Shape Prior这个概念。
为了处理同一个类别中不同实例形状的不同,本文创建了一个网络对"从预学习类形状先验的变换(deformation from a pre-learned categorical shape piror)"进行显式建模,来重建三维对象模型。然后网络推断观测的类实例深度与重建的3D模型的密集对应关系(dense correspondence)
In this work, we propose to reconstruct the complete object models in the NOCS to capture the intra-class shape variation.
重建NOCS空间中的完整模型,这个模型要尽可能能够包含同一类不同实例的所有变化。
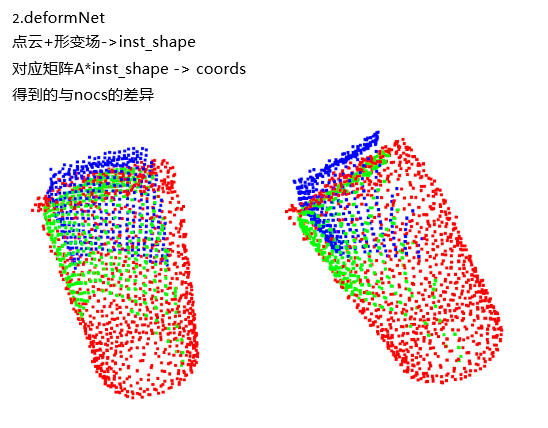
放一点自己复现的结果:
inst_shape:红色
coord:绿色
nocs:蓝色
# Method
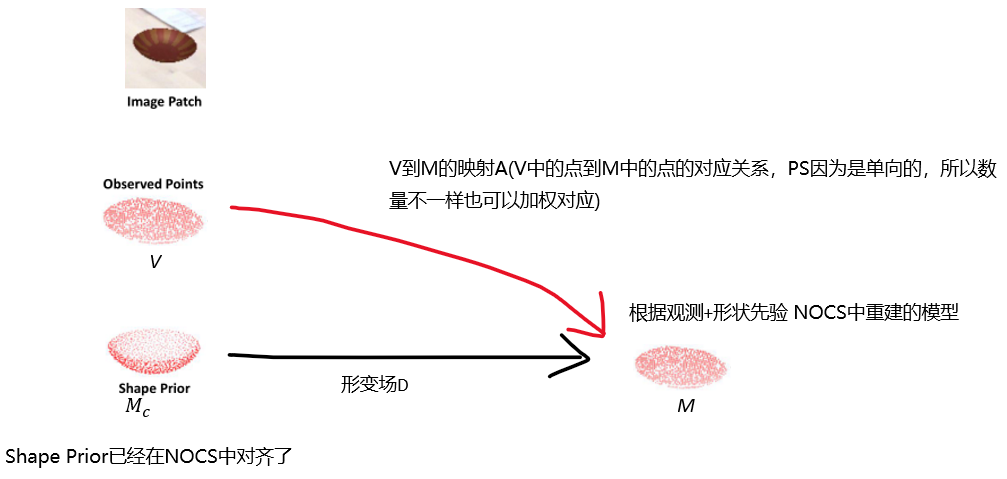
给定一个RGB-D图像作为输入,我们的目标是检测并定位3D空间中的所有可见对象实例。之前未看到对象实例,但必须来自已知类别。每个对象由一个类标签和一个amodal 3D边界框表示,该边界框由其6D姿势和大小参数化。6D姿势定义为刚体变换(即旋转和平移),该变换将对象从参考变换到相机坐标系。在实例级6D对象姿势估计中,通常选择给定三维对象模型的坐标系作为参考。不幸的是,这对于我们的类别级任务是不可行的,因为3D模型的实例不可用。为了缓解这个问题,我们利用标准化对象坐标空间(NOCS)——一种在[33]中提出的类别内所有可能对象实例的共享规范表示。然后,将分类的6D对象姿势和大小估计问题简化为查找每个对象实例的观测深度图与其在NOCS(即NOCS坐标)中的对应点之间的相似性变换。
与NOCS[33]中直接从卷积神经网络(CNN)输出NOCS坐标的方法不同,我们提出了一个中间步骤,用于在改进类内形状变化的学习之前估计预学习形状的变形。我们的形状先验是从跨越所有类别的模型集合中学习的(第3.1节)。如图1所示,我们的方法包括三个阶段。第一阶段使用现成的网络(例如Mask R-CNN[7])对彩色图像执行实例分割。接下来,我们将遮罩深度贴图转换为具有每个实例的摄影机内部参数的点云,并根据遮罩的边界框裁剪图像面片。将点云、图像面片和相应的形状先验作为输入,我们的网络输出一个变形场,该变形场将形状先验变形为所需对象实例的形状(也称为重建模型)。此外,我们的网络输出一组对应关系,将从对象实例的观察深度图获得的点云中的每个点与重建模型的点相关联。这组对应关系用于将重建模型屏蔽为NOCS坐标(第3.2节)。最后,通过注册NOCS坐标和从观测深度图获得的点云,可以估计物体的6D姿势和大小(第3.3节)。
# 关于训练数据增强
在以往的3D目标检测任务中,在线数据增强技术(如平移、随机翻转、移位、缩放和旋转)应用于原始点云,以增强训练数据。但是,这些操作无法更改对象的形状属性。在点云上简单地采用这些操作无法处理3D任务中的形状变化问题。为了解决这个问题,[7]提出了部件感知增强,它通过五种操作操作3D对象的语义部件:dropout、交换(swap)、混合(mix)、?(sparing)和噪声注入。然而,如何确定语义部分是不明确的。文中提出了一种基于盒子框架的三维数据增强机制,该机制可以生成各种形状变体,并避免语义部分决策过程。
# 类形状先验(Categorical Shape Prior)
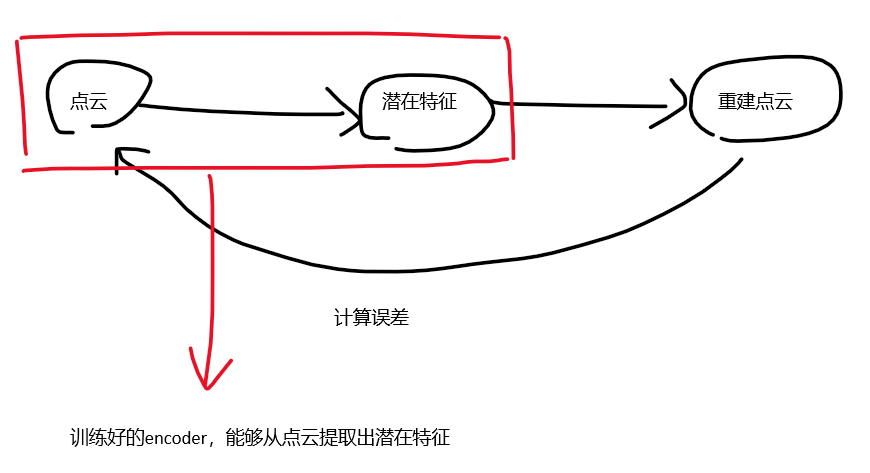
尽管不同实例的对象形状不同,但相同类别的对象(尤其是人造物体)往往具有语义和几何相似的组件。例如,照相机通常由一个类似长方体的机身和一个柱形的镜头组成;杯子通常是带把手的圆柱形。**这些分类特征为新实例(没见过的物体)的形状重建提供了非常好的前提。我们建议学习平均形状,以从每个类别的所有可用模型中捕获高级特征。**为此,我们首先用所有可用的对象模型训练一个自动编码器,然后用编码器计算每个对象类别的平均潜在特征(mean latent embedding)。这些潜在特征被传递到解码器中,以获得每个对象类别的平均形状先验。与对体素表示进行操作的简单平均[30]和主成分分析(PCA)[3]等方法不同,该自动编码器框架可以很容易地改变,以采用任何3D表示。
给定一组3D点云模型,分别为每个模型进行一个相似变换,使其在NOCS中能够正确地对齐。这个相似变换确保学习出的形状先验与要重建的目标形状具有相同的比例和方向。encoder****将点云作为输入并输出低维特征向量,即前面提到的“潜在特征”,decoder将该特征作为输入,输出通过输入重建的点云
# 提取潜在特征
只要理解了什么是形状先验Shape Prior就知道了什么是deformation,但这里姑且说一下:deformation field,形变场,这个词常在医学影像配准中出现。一个大小为[W,H]的二维图像对应的形变场的大小是[W,H,2],其中第三个维度的大小为2,分别表示在x轴和y轴方向的位移。同理,一个大小为[D,W,H]的三维图像对应的形变场的大小是[D,W,H,3],其中第三个维度的大小为3,分别表示在x轴、y轴和z轴方向的位移。下图是一个二维脑部图像配准后得到的形变场(参考 https://blog.csdn.net/zuzhiang/article/details/107423465).

使用自编码器来学习Categorical Shape Prior。注意:训练encoder时使用的每个模型都单独应用一个相似性变换(similarity transformation),使其在NOCS中对齐,确保所学习的形状先验与要重建的目标形状有相同的比例和方向
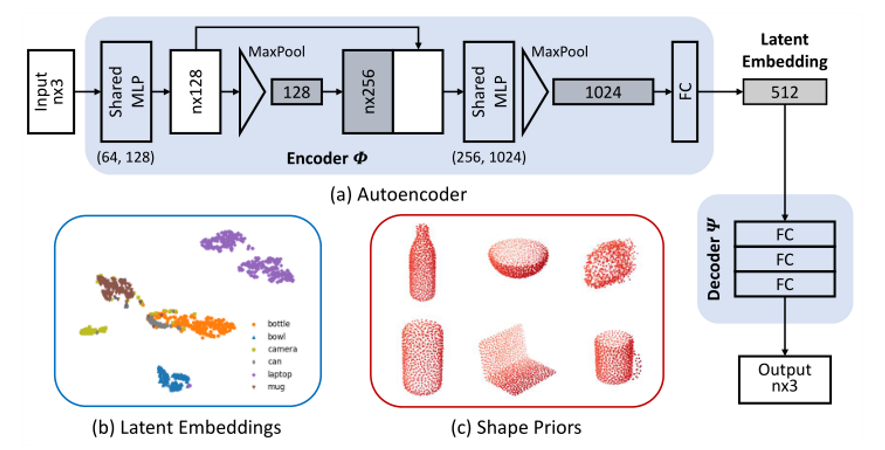
 自动编码器结构
自动编码器结构
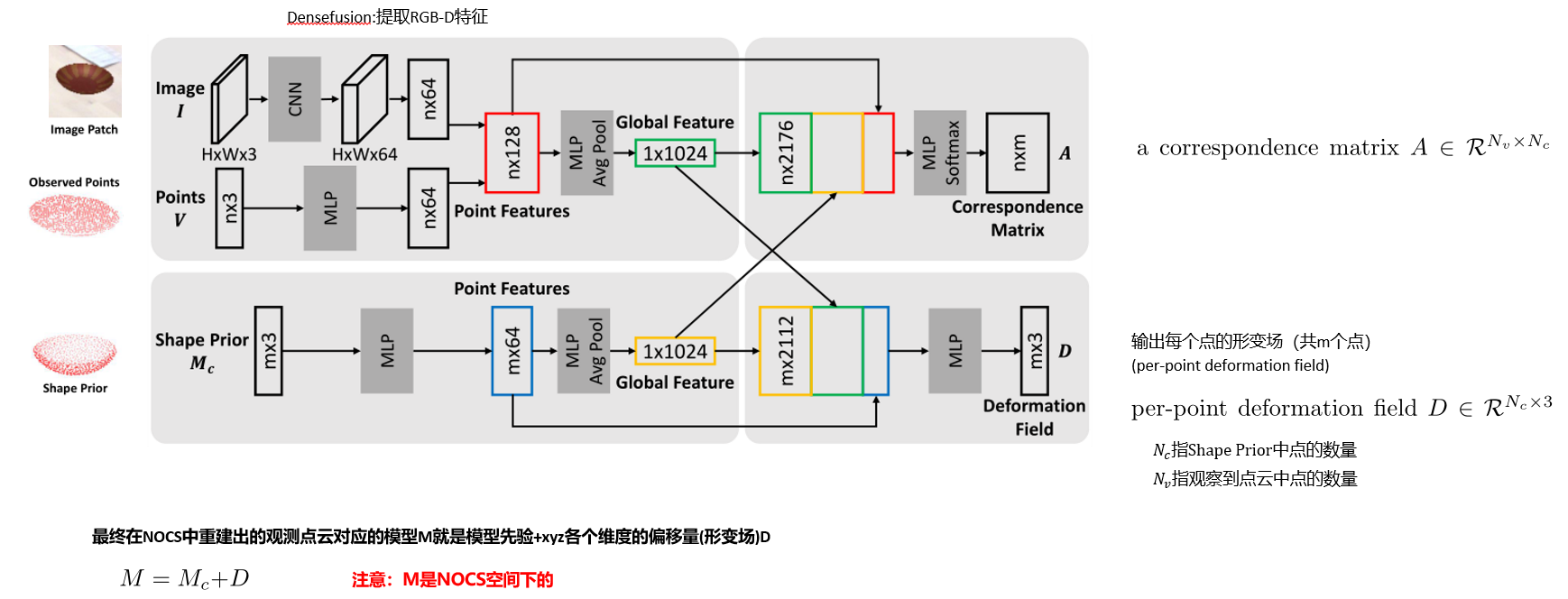


形状先验M_c 提供类别的先验知识,即粗糙形状几何体和标准位姿。尽管观测到的RGBD即(V,I)是局部的,但它提供了目标形状的特定于实例的细节。因此可以通过(V,I)的指导使M_c 变形来重建NOCS中对象。(公式从onenote复制过来怎么就裂了...)

因此,将类别和实例全局特征连接起来,并用连接的特征丰富类别点特征。
将获得的特征向量依次与1×1核卷积,生成变形场D。类似的直觉和特征拼接策略也适用于A的估计。我们结合实例点特征和全局特征,聚合每个点的局部和全局信息。V中的每个点通过与类别全局特征串联,映射到重构模型的点。我们通过将A和M相乘得到V中点的NOCS坐标,表示为P,即。
# Loss
损失函数包含3部分
重建模型的损失,对应矩阵A的损失(通过监督预测的NOCS点来间接监督)以及正规化损失(Regularization Losses),这个Regularization Losses比较有意思,文章中说:

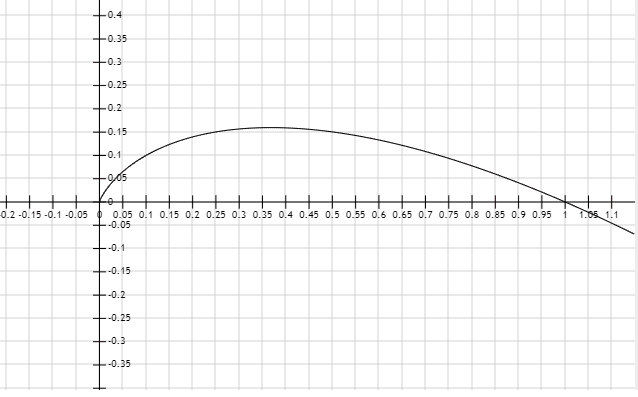
上图为y=xlogx的图像,取负号就是将该图倒过来。损失函数的值想要取得最小,那么x的值必定会趋向于0或者1,最终导致的结果就是得到文中说的“趋向于peak分布的one-hot向量”