# NOCS数据集
# class id 与对应关系
1:'02876657', Bottle
2:'02880940',Bowl
3:'02942699',Camera
4:'02946921',Can
5:'03642806',Laptop
6:'03797390',Mug
# obj_model
在obj_model数据集下的数据结构应该是
obj_model
Train 合成数据集的
Xxx(这些都是同一类的模型)
Xxxxx(这些都是单个模型)
Model.obj
Model.mtl
Bbox.txt
Xxxxx
Xxxxx
…
Xxx
Xxx
Xxx
…
Val 合成数据及的
Real_train
Real_test

其实不止SPD,大部分的工作都对mug类进行了额外处理。
# SPD的处理
总结: 不建议看SPD的处理代码
SPD在预处理数据集的时候是分了三波处理的 camera_trian real_train camera+real test
1.在处理camera_train的时候,将深度图反投影得到点云pts,coord图计算点云coord_pts 这两个点云计算相似变换,得到sRT

在align_nocs_to_depth中估计相似矩阵
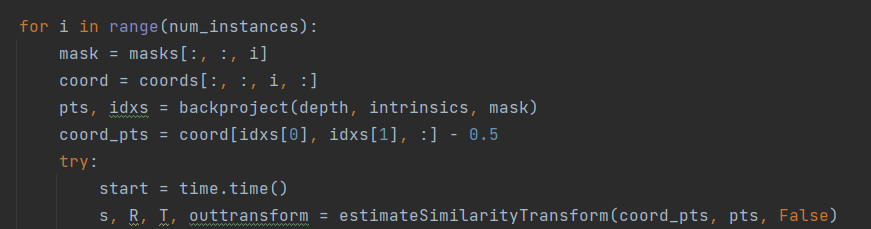
2.在处理real_train时
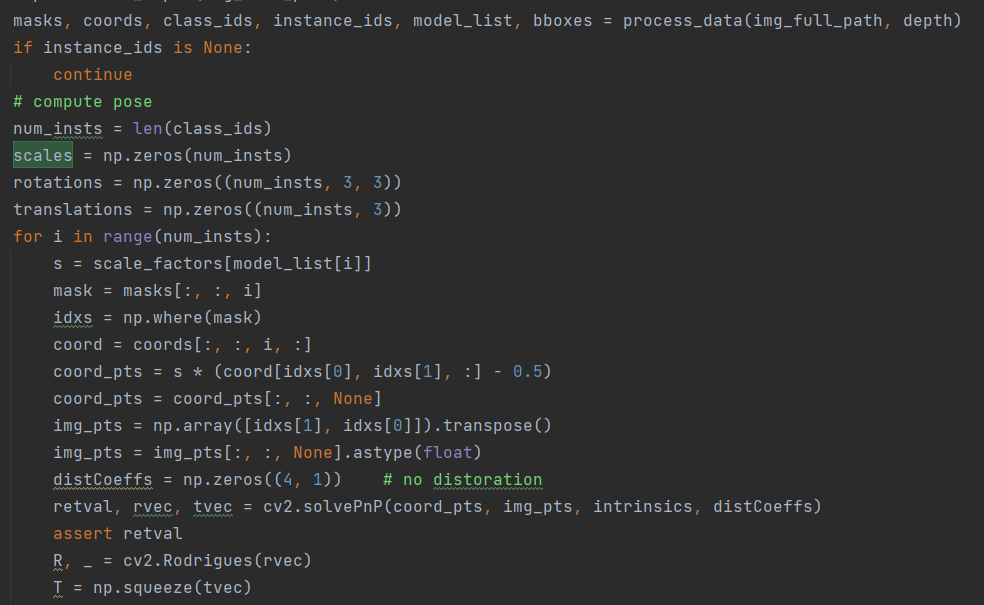
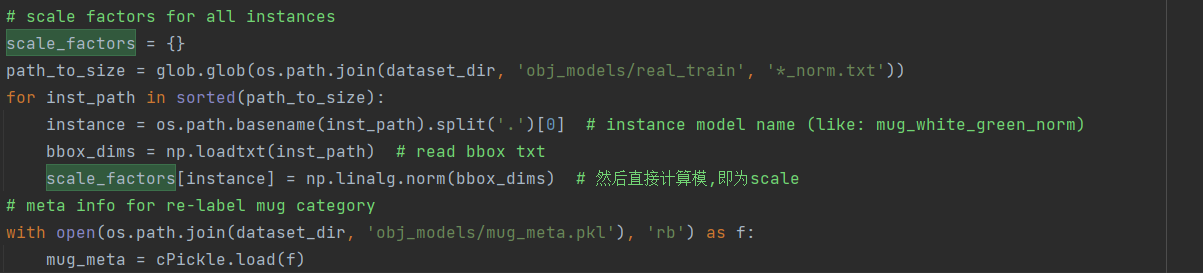
可以看到缩放s是直接从字典scale_factors中根据model_list[i](obj模型的名字)读取的,也就是说一个模型固定对应一个缩放,与场景无关。 而缩放是从obj_model下雨.obj文件同目录的.txt中读取的,txt中只有三个数,这三个数组成的向量的模就是该模型的scale
 读取到scale之后,用来将_coord.png的颜色值 转为点云
具体是怎么转换的:
读取_coord.png,交换维度满足BGR,将其由0~255映射到0~1,(还对Z进行了反转0.2变1-0.2=0.8这种)
然后与mask结合,分别与每个实例的mask相乘
得到coords,第0,1,3维是处理后的RGB值,第2维是实例,也就是说coord[:,:,0,:]是实例序号是0的coord
可以理解成_coord.png的颜色值都被处理为0到1之间的,即xyz是[0,1]
将xyz映射到[-s*0.5,s*0.5],也就是将coord_pts放大s倍,然后用放大后的去
读取到scale之后,用来将_coord.png的颜色值 转为点云
具体是怎么转换的:
读取_coord.png,交换维度满足BGR,将其由0~255映射到0~1,(还对Z进行了反转0.2变1-0.2=0.8这种)
然后与mask结合,分别与每个实例的mask相乘
得到coords,第0,1,3维是处理后的RGB值,第2维是实例,也就是说coord[:,:,0,:]是实例序号是0的coord
可以理解成_coord.png的颜色值都被处理为0到1之间的,即xyz是[0,1]
将xyz映射到[-s*0.5,s*0.5],也就是将coord_pts放大s倍,然后用放大后的去
3.test size是通过model_size得到的,model_size则是对物体的xyz每个维度找一个最大值然后乘以2,即找了一个3D bbox s则是通过sRT中的R,因为旋转矩阵满足RR-1 = I,所以可以计算出s,而sRT的来源又是camera_test_result.pkl,这个 来自NOCS
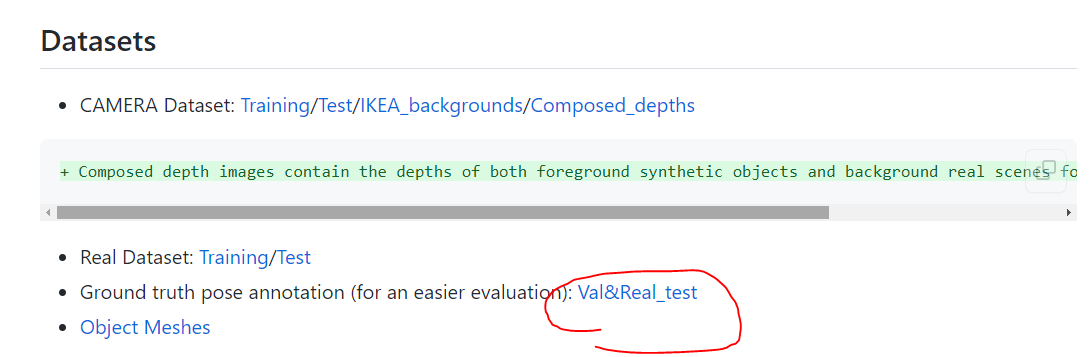
下载后名为gts.zip,是根据scene_inst_prefix来读取的
每个pkl文件可以得到

使用的sRT就是来自这里
pts = sRT*coord_pts 所以scale(代码中是s)就是指coord到pts的缩放,而size,则是物体在nocs下的尺寸,因为坐标在coord.png中作为颜色值存储0~255,而png的数据类型是uint8(范围是[0,255]),因此想要存储坐标就不得不面临缩放。需要用size将其恢复到原始尺寸。那么在缩放的时候最好的方法就是按对角线归一化,因此需要xyz的最大值。
那么,为什么camera_train计算相似矩阵,real_train用pnp,test又直接读取呢?